
علم داده چیست؟
علم داده مطالعه و تحلیل دادهها برای استخراج بینشهای ارزشمند است که میتواند به بهبود تصمیمگیریها و عملکرد سازمانها کمک کند. این حوزه ترکیبی از روشها و اصول ریاضی، آمار، هوش مصنوعی و علوم کامپیوتر است که برای پردازش و تحلیل حجم انبوه دادهها به کار گرفته میشود. دانشمندان داده به کمک این تحلیلها پاسخهایی برای پرسشهایی مانند "چه اتفاقی افتاده است؟"، "چرا این اتفاق رخ داده است؟"، "چه اتفاقاتی در آینده ممکن است رخ دهد؟" و "چگونه میتوان از این نتایج استفاده کرد؟" پیدا میکنند.
علم داده فراتر از یک علم تئوری است و به سازمانها کمک میکند دادهها را به اطلاعات کاربردی تبدیل کنند. برای مثال، شرکتهای خردهفروشی میتوانند با استفاده از دادههای مشتریان، الگوهای خرید را شناسایی کرده و پیشنهادات شخصیسازی شده ارائه دهند. همچنین، بیمارستانها میتوانند با تحلیل دادههای بیماران، بیماریهای بالقوه را پیشبینی کرده و از وقوع آنها پیشگیری کنند. این حوزه نقش کلیدی در ارتقای تصمیمگیریهای استراتژیک، کاهش هزینهها و افزایش سودآوری کسبوکارها ایفا میکند.
اهمیت علم داده
سازمانها با حجم زیادی از دادهها مواجه هستند که توسط دستگاهها و سیستمهای مختلف جمعآوری و ذخیره میشوند. دادههای جمعآوریشده میتوانند شامل اطلاعات متنی، صوتی، تصویری یا ویدئویی باشند. علم داده ابزارها و روشهایی را ارائه میدهد که این دادهها را به اطلاعات ارزشمند تبدیل کرده و به سازمانها کمک میکند تصمیمات آگاهانه بگیرند و مزیت رقابتی خود را حفظ کنند.
علاوه بر این، علم داده موجب بهینهسازی فرآیندها، شناسایی فرصتهای جدید کسبوکار و حل چالشهای پیچیده میشود. بهعنوان مثال، در حوزه مالی، بانکها از علم داده برای شناسایی فعالیتهای مشکوک و پیشگیری از تقلب استفاده میکنند. در صنعت بهداشت و درمان، دادهها برای پیشبینی بیماریها و بهبود برنامهریزی درمانی به کار گرفته میشوند. همچنین، شرکتهای تجارت الکترونیک با تحلیل رفتار مشتریان، تجربه خرید را شخصیسازی کرده و فروش خود را افزایش میدهند. این حوزه در صنایع مختلفی مانند بهداشت و درمان، مالی، تجارت الکترونیک و حملونقل کاربرد دارد.
تاریخچه علم داده
علم داده یک مفهوم جدید نیست، اما معنای آن در طول زمان تغییر کرده است. در دهه ۱۹۶۰ این واژه بهعنوان جایگزینی برای آمار مطرح شد و در دهه ۱۹۹۰ متخصصان علوم کامپیوتر آن را بهعنوان حوزهای مستقل تعریف کردند که شامل طراحی داده، جمعآوری و تحلیل داده است. با گذشت زمان و پیشرفت فناوری، این مفهوم در خارج از محیطهای دانشگاهی نیز بهطور گستردهای مورد استفاده قرار گرفت.
در دهههای اخیر، پیشرفتهای فناوری مانند رایانش ابری(cloud computing) و یادگیری ماشین (machine learning)باعث افزایش سرعت و دقت تحلیل دادهها شده است. رایانش ابری امکان ذخیرهسازی و پردازش حجم بالایی از دادهها را با هزینه کمتر فراهم کرده و یادگیری ماشین توانسته است با خودکارسازی تحلیلها، به کشف الگوهای پیچیده کمک کند. این پیشرفتها علم داده را به یکی از مهمترین ابزارها در تصمیمگیریهای مدرن تبدیل کرده است.
علم داده و رایانش ابری(Data science و cloud computing)
رایانش ابری امکان مقیاسپذیری علم داده را با ارائه دسترسی به قدرت پردازش بیشتر، فضای ذخیرهسازی و ابزارهای موردنیاز برای پروژههای علم داده فراهم میکند.
از آنجا که علم داده اغلب با مجموعههای بزرگ داده سروکار دارد، استفاده از ابزارهایی که بتوانند با حجم دادهها مقیاس پیدا کنند، بهویژه برای پروژههای حساس به زمان، بسیار حائز اهمیت است. راهکارهای ذخیرهسازی ابری، مانند دیتا لیکها، دسترسی به زیرساختهای ذخیرهسازی را فراهم میکنند که میتوانند به راحتی حجم بالایی از دادهها را جمعآوری و پردازش کنند. این سیستمهای ذخیرهسازی انعطافپذیری لازم را برای کاربران نهایی فراهم میکنند و به آنها امکان میدهند تا در صورت نیاز، خوشههای بزرگتری را راهاندازی کنند. همچنین، میتوانند گرههای محاسباتی بیشتری را اضافه کنند تا وظایف پردازش داده را سریعتر انجام دهند و به کسبوکارها این امکان را بدهند که بین اهداف کوتاهمدت و نتایج بلندمدت تعادل برقرار کنند.
فناوریهای متنباز بهطور گستردهای در مجموعه ابزارهای علم داده استفاده میشوند. زمانی که این ابزارها در ابر میزبانی میشوند، تیمها نیازی به نصب، پیکربندی، نگهداری یا بهروزرسانی آنها به صورت محلی ندارند. چندین ارائهدهنده خدمات ابری، از جمله IBM Cloud®، مجموعههای ابزار آمادهای ارائه میدهند که به دانشمندان داده امکان میدهد بدون نیاز به کدنویسی مدلسازی کنند، که این امر دسترسی به نوآوریهای فناوری و بینشهای داده را برای کاربران بیشتری ممکن میسازد.
آینده علم داده
نوآوریهای هوش مصنوعی و یادگیری ماشین باعث شدهاند پردازش دادهها سریعتر و کارآمدتر شود. تقاضای صنعت یک اکوسیستم شامل دورهها، مدارک تحصیلی و موقعیتهای شغلی در حوزه علم داده ایجاد کرده است. به دلیل مهارتها و تخصص چندوظیفهای موردنیاز، علم داده در دهههای آینده رشد چشمگیری خواهد داشت.
موارد استفاده از علم داده
علم داده برای بررسی دادهها به چهار روش اصلی مورد استفاده قرار میگیرد:
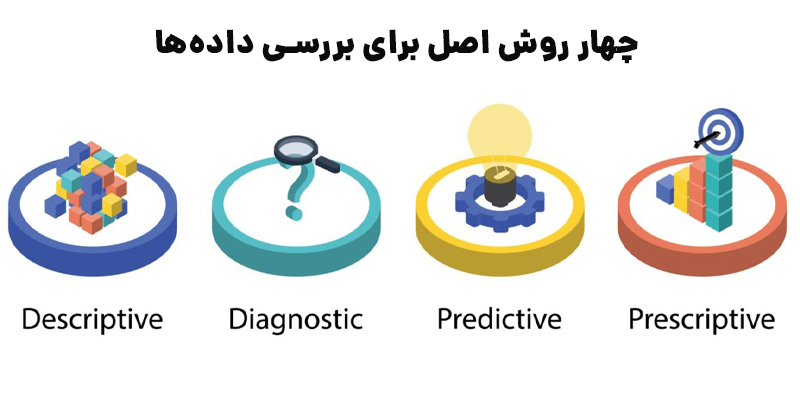
1. تحلیل توصیفی (Descriptive Analysis)
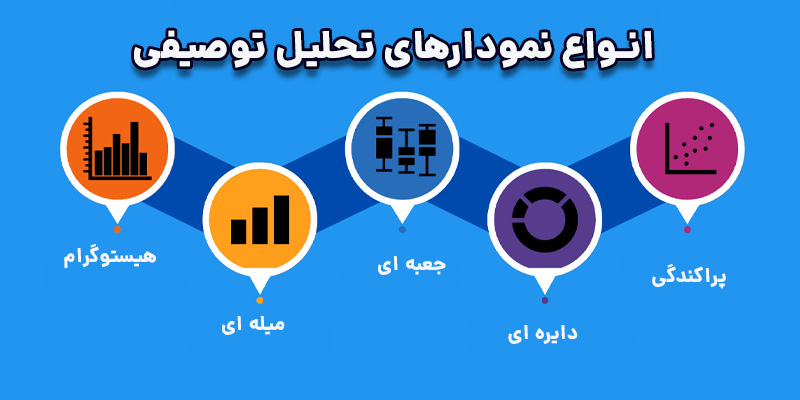
تحلیل توصیفی دادهها را بررسی میکند تا بینشی از آنچه اتفاق افتاده یا در حال وقوع است، به دست آورد. این تحلیل معمولاً با استفاده از تصویریسازی دادهها مانند نمودارهای دایرهای، میلهای، خطی، جداول یا روایتهای تولیدشده انجام میشود.
بهعنوان مثال، یک سرویس رزرو پرواز ممکن است دادههایی مانند تعداد بلیطهای رزرو شده در هر روز را ثبت کند. تحلیل توصیفی میتواند زمانهای اوج رزرو، کاهش رزرو و ماههای پربازده این سرویس را نشان دهد.
2. تحلیل تشخیصی (Diagnostic Analysis)
تحلیل تشخیصی یک بررسی عمیق یا جزئیات دقیق دادهها برای درک دلایل وقوع یک رویداد است. این تحلیل با استفاده از تکنیکهایی مانند درل داون (drill-down)، کشف داده، دادهکاوی و تحلیل همبستگیها انجام میشود.
برای مثال، سرویس پرواز ممکن است یک ماه پربازده خاص را بررسی کند تا دلیل افزایش رزروها را بفهمد. این بررسی ممکن است نشان دهد که بسیاری از مشتریان برای شرکت در یک رویداد ورزشی ماهانه به یک شهر خاص سفر کردهاند.
3. تحلیل پیشبینی (Predictive Analysis)
تحلیل پیشبینی از دادههای تاریخی برای پیشبینی دقیق الگوهای دادهای که ممکن است در آینده رخ دهد، استفاده میکند. این تحلیل با تکنیکهایی مانند یادگیری ماشین، پیشبینی، تطبیق الگوها و مدلسازی پیشبینی مشخص میشود.
بهعنوان مثال، تیم سرویس پرواز ممکن است از علم داده برای پیشبینی الگوهای رزرو پرواز در سال آینده استفاده کند. الگوریتم ممکن است با بررسی دادههای گذشته، افزایش رزرو برای مقصدهای خاص در ماه می را پیشبینی کند. این شرکت میتواند از فوریه تبلیغات هدفمند برای آن شهرها آغاز کند.
4. تحلیل تجویزی (Prescriptive Analysis)
تحلیل تجویزی گامی فراتر از تحلیل پیشبینی است. این تحلیل نه تنها پیشبینی میکند که چه اتفاقی ممکن است رخ دهد، بلکه پاسخ بهینه به آن رویداد را نیز پیشنهاد میدهد. تحلیل تجویزی با استفاده از تکنیکهایی مانند تحلیل گراف، شبیهسازی، پردازش رویدادهای پیچیده، شبکههای عصبی و موتورهای توصیهگر مبتنی بر یادگیری ماشین انجام میشود.
در مثال رزرو پرواز، تحلیل تجویزی میتواند کمپینهای بازاریابی گذشته را بررسی کند تا از افزایش رزروهای پیشبینیشده نهایت استفاده را ببرد. دانشمند داده میتواند نتایج رزرو را برای سطوح مختلف بودجه بازاریابی در کانالهای مختلف پیشبینی کند. این پیشبینیها به شرکت رزرو پرواز کمک میکند با اطمینان بیشتری تصمیمات بازاریابی خود را اتخاذ کند.
مزایای علم داده برای کسبوکار
علم داده در حال متحول کردن شیوه عملکرد شرکتها است. بسیاری از کسبوکارها، صرفنظر از اندازه، به یک استراتژی قدرتمند علم داده نیاز دارند تا رشد خود را پیش ببرند و مزیت رقابتی خود را حفظ کنند. برخی از مزایای کلیدی شامل موارد زیر میشود:
کشف الگوها و روابط جدید تحولآفرین
علم داده به کسبوکارها این امکان را میدهد که الگوها و روابط جدیدی را کشف کنند که میتوانند سازمان را متحول کنند. این علم میتواند تغییرات کمهزینهای در مدیریت منابع پیشنهاد دهد که تأثیر زیادی بر حاشیه سود دارند.
برای مثال، یک شرکت تجارت الکترونیک با استفاده از علم داده متوجه میشود که تعداد زیادی از درخواستهای مشتریان خارج از ساعات کاری ایجاد میشود. بررسیها نشان میدهد مشتریانی که پاسخ سریع دریافت میکنند، بیشتر احتمال دارد خرید خود را تکمیل کنند. با راهاندازی خدمات مشتری ۲۴/۷، این شرکت درآمد خود را ۳۰٪ افزایش میدهد.
نوآوری در محصولات و راهکارهای جدید
علم داده میتواند شکافها و مشکلاتی را شناسایی کند که در غیر این صورت نادیده گرفته میشدند. بینش عمیقتر درباره تصمیمات خرید، بازخورد مشتریان و فرآیندهای کسبوکار میتواند باعث نوآوری در عملیات داخلی و راهکارهای خارجی شود.
برای مثال، یک راهکار پرداخت آنلاین از علم داده برای جمعآوری و تحلیل نظرات مشتریان درباره شرکت در شبکههای اجتماعی استفاده میکند. تحلیلها نشان میدهد که مشتریان در زمان اوج خرید، رمز عبور خود را فراموش میکنند و از سیستم فعلی بازیابی رمز عبور ناراضی هستند. این شرکت میتواند یک راهحل بهتر طراحی کند و افزایش چشمگیری در رضایت مشتریان مشاهده کند.
بهینهسازی بلادرنگ
برای کسبوکارها، بهویژه شرکتهای بزرگ، پاسخگویی به شرایط متغیر در لحظه بسیار چالشبرانگیز است. این امر میتواند باعث زیانهای قابلتوجه یا اختلال در فعالیتهای تجاری شود. علم داده میتواند به شرکتها کمک کند تغییرات را پیشبینی کنند و بهطور بهینه به شرایط مختلف واکنش نشان دهند.
برای مثال، یک شرکت حملونقل کامیونی از علم داده برای کاهش زمان از کارافتادگی کامیونها در صورت خرابی استفاده میکند. آنها مسیرها و الگوهای کاری که منجر به خرابی سریعتر میشوند را شناسایی کرده و برنامه زمانی کامیونها را اصلاح میکنند. همچنین، یک موجودی از قطعات یدکی رایج که نیاز به تعویض مکرر دارند ایجاد میکنند تا تعمیر کامیونها سریعتر انجام شود.
فرآیند علم داده چیست؟
فرآیند علم داده معمولاً با یک مشکل کسبوکار آغاز میشود. یک دانشمند داده با ذینفعان کسبوکار همکاری میکند تا نیازهای سازمان را درک کند. پس از تعریف مسئله، دانشمند داده میتواند با استفاده از فرآیند علم داده OSEMN آن را حل کند:
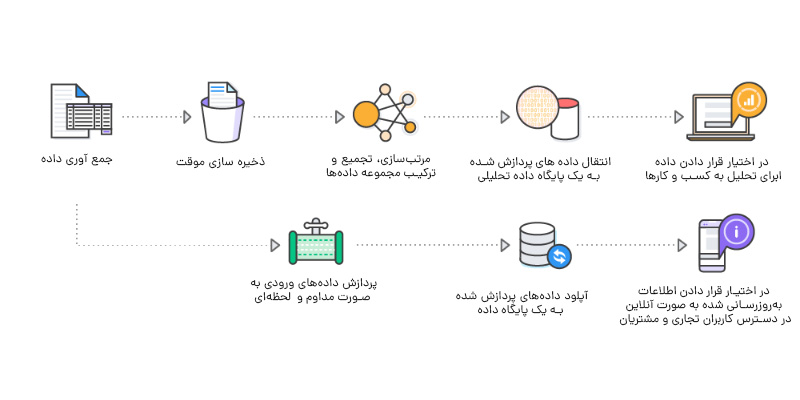
O – جمعآوری دادهها (Obtain data)
دادهها ممکن است از قبل وجود داشته باشند، بهتازگی جمعآوری شده باشند یا از مخازن دادهای که از اینترنت قابل دانلود هستند، استخراج شوند. دانشمندان داده میتوانند دادهها را از پایگاههای داده داخلی یا خارجی، نرمافزارهای مدیریت ارتباط با مشتری (CRM) شرکت، لاگ سرورهای وب، شبکههای اجتماعی یا از منابع معتبر ثالث خریداری کنند.
S – پاکسازی دادهها (Scrub data)
پاکسازی دادهها، یا تمیز کردن دادهها، فرآیندی است که طی آن دادهها مطابق با یک فرمت از پیش تعیینشده استانداردسازی میشوند. این فرآیند شامل رفع دادههای ناقص، اصلاح خطاها و حذف دادههای خارج از محدوده (Outliers) میشود. برخی از نمونههای پاکسازی داده عبارتند از:
تغییر تمام مقادیر تاریخ به یک فرمت استاندارد.
اصلاح اشتباهات املایی یا حذف فضاهای اضافی.
اصلاح خطاهای ریاضی یا حذف کاما از اعداد بزرگ.
E – بررسی دادهها (Explore data)
بررسی دادهها یک تحلیل اولیه است که برای برنامهریزی استراتژیهای مدلسازی بعدی استفاده میشود. دانشمندان داده با استفاده از آمار توصیفی و ابزارهای تصویریسازی داده، درک اولیهای از دادهها به دست میآورند. سپس دادهها را برای شناسایی الگوهای جالب که میتوان مطالعه یا اجرا کرد، بررسی میکنند.
M – مدلسازی دادهها (Model data)
برای درک عمیقتر، پیشبینی نتایج و پیشنهاد بهترین اقدامات، از نرمافزارها و الگوریتمهای یادگیری ماشین استفاده میشود. تکنیکهایی مانند ارتباطگذاری (Association)، طبقهبندی (Classification) و خوشهبندی (Clustering) روی مجموعه دادههای آموزشی اعمال میشوند. مدل ممکن است با دادههای آزمایشی از پیش تعیینشده آزمایش شود تا دقت نتایج ارزیابی شود. مدل دادهها میتواند چندین بار برای بهبود نتایج اصلاح شود.
N – تفسیر نتایج (Interpret results)
دانشمندان داده با تحلیلگران و کسبوکارها همکاری میکنند تا بینشهای داده را به اقدامات عملی تبدیل کنند. آنها از نمودارها، گرافها و چارتها برای نمایش روندها و پیشبینیها استفاده میکنند. خلاصهسازی دادهها به ذینفعان کمک میکند تا نتایج را بهخوبی درک کرده و بهطور مؤثر اجرا کنند.
تکنیکهای علم داده
متخصصان علم داده از سیستمهای محاسباتی برای اجرای فرآیند علم داده استفاده میکنند. تکنیکهای اصلی مورد استفاده توسط دانشمندان داده عبارتند از:
طبقهبندی (Classification)
طبقهبندی فرآیند مرتبسازی دادهها به گروهها یا دستههای خاص است. کامپیوترها برای شناسایی و مرتبسازی دادهها آموزش میبینند. مجموعه دادههای شناختهشده برای ساخت الگوریتمهای تصمیمگیری در کامپیوتر استفاده میشوند تا دادهها را بهسرعت پردازش و دستهبندی کنند.
نمونههایی از کاربرد طبقهبندی:
مرتبسازی محصولات به عنوان محبوب یا غیرمحبوب.
طبقهبندی درخواستهای بیمه به عنوان پرخطر یا کمخطر.
دستهبندی نظرات شبکههای اجتماعی به مثبت، منفی یا خنثی.
رگرسیون (Regression)
رگرسیون روشی برای پیدا کردن رابطه بین دو نقطه داده ظاهراً نامرتبط است. این رابطه معمولاً بر اساس یک فرمول ریاضی مدلسازی شده و به صورت نمودار یا منحنیها نمایش داده میشود. هنگامی که مقدار یک نقطه داده شناخته شده باشد، رگرسیون برای پیشبینی نقطه داده دیگر استفاده میشود.
نمونههایی از کاربرد رگرسیون:
نرخ انتشار بیماریهای هوابرد.
رابطه بین رضایت مشتری و تعداد کارکنان.
رابطه بین تعداد ایستگاههای آتشنشانی و تعداد مصدومان ناشی از آتشسوزی در یک مکان خاص.
خوشهبندی (Clustering)
خوشهبندی روشی برای گروهبندی دادههای نزدیک به هم برای جستجوی الگوها و ناهنجاریها است. خوشهبندی با طبقهبندی تفاوت دارد، زیرا دادهها نمیتوانند بهطور دقیق در دستههای ثابت طبقهبندی شوند. بنابراین دادهها بر اساس روابط احتمالی گروهبندی میشوند. با خوشهبندی میتوان الگوها و روابط جدیدی کشف کرد.
نمونههایی از کاربرد خوشهبندی:
گروهبندی مشتریان با رفتار خرید مشابه برای بهبود خدمات مشتری.
گروهبندی ترافیک شبکه برای شناسایی الگوهای استفاده روزانه و شناسایی سریعتر حملات شبکه.
خوشهبندی مقالات به چندین دسته خبری مختلف و استفاده از این اطلاعات برای شناسایی محتوای اخبار جعلی.
اصل اساسی تکنیکهای علم داده
اگرچه جزئیات تکنیکها متفاوت است، اصول زیر در تمام آنها مشترک است:
آموزش ماشین برای مرتبسازی دادهها بر اساس یک مجموعه داده شناختهشده. بهعنوان مثال، کلمات نمونه با مقدار مرتبسازی مشخص به کامپیوتر داده میشوند. کلمه «خوشحال» مثبت است، در حالی که «نفرت» منفی است.
ارائه دادههای ناشناخته به ماشین و اجازه دادن به آن برای مرتبسازی مستقل مجموعه داده.
پذیرش احتمال وجود خطا در نتایج و مدیریت عامل احتمالات در نتایج.
در دوره پیشرفته آموزش Machine Learning ML.NET تمام این موارد را به صورت کامل و کاربردی آموزش می دهیم.
فناوریهای مختلف در علم داده
متخصصان علم داده با فناوریهای پیچیدهای کار میکنند، از جمله:
هوش مصنوعی (Artificial Intelligence): مدلهای یادگیری ماشین و نرمافزارهای مرتبط برای تحلیل پیشبینیکننده و تجویزی استفاده میشوند.
رایانش ابری (Cloud Computing): فناوریهای ابری انعطافپذیری و قدرت پردازشی موردنیاز برای تحلیل پیشرفته دادهها را به دانشمندان داده ارائه میدهند.
اینترنت اشیا (IoT): اینترنت اشیا به دستگاههای مختلفی اشاره دارد که میتوانند بهصورت خودکار به اینترنت متصل شوند. این دستگاهها دادههایی را برای پروژههای علم داده جمعآوری میکنند و حجم عظیمی از دادهها را تولید میکنند که برای دادهکاوی و استخراج دادهها قابل استفاده است.
رایانش کوانتومی (Quantum Computing): رایانههای کوانتومی میتوانند محاسبات پیچیده را با سرعت بالا انجام دهند. دانشمندان داده ماهر از این سیستمها برای ساخت الگوریتمهای کمی پیچیده استفاده میکنند.
مقایسه علم داده با حوزههای مرتبط
علم داده یک اصطلاح جامع است که شامل نقشها و زمینههای مرتبط با داده میشود. در اینجا به مقایسه برخی از آنها میپردازیم:
تفاوت بین علم داده و تحلیل داده چیست؟
در حالی که این دو اصطلاح ممکن است به جای یکدیگر استفاده شوند، تحلیل داده زیرمجموعهای از علم داده است. علم داده یک اصطلاح کلی برای تمام جنبههای پردازش دادهها—از جمعآوری تا مدلسازی و استخراج بینش—است.
در مقابل، تحلیل داده بیشتر بر آمار، ریاضیات و تحلیل آماری متمرکز است. تحلیل داده فقط با تحلیل دادهها سروکار دارد، در حالی که علم داده به تصویر بزرگتر مرتبط با دادههای سازمانی میپردازد.
در محیطهای کاری، دانشمندان داده و تحلیلگران داده معمولاً با یکدیگر برای دستیابی به اهداف مشترک کسبوکار همکاری میکنند. یک تحلیلگر داده ممکن است زمان بیشتری را صرف تحلیلهای روتین و ارائه گزارشهای منظم کند، در حالی که دانشمند داده ممکن است روشهای ذخیرهسازی، پردازش و تحلیل دادهها را طراحی کند. بهطور ساده، تحلیلگر داده از دادههای موجود معنا استخراج میکند، در حالی که دانشمند داده روشها و ابزارهای جدیدی برای پردازش داده ایجاد میکند.
تفاوت بین علم داده و تحلیل کسبوکار چیست؟
در حالی که بین علم داده و تحلیل کسبوکار همپوشانی وجود دارد، تفاوت اصلی در میزان استفاده از فناوری است. دانشمندان داده بیشتر با فناوریهای داده کار میکنند، در حالی که تحلیلگران کسبوکار بین کسبوکار و IT پل میزنند.
تحلیلگران کسبوکار نیازهای کسبوکار را تعریف میکنند، اطلاعات را از ذینفعان جمعآوری کرده یا راهحلها را اعتبارسنجی میکنند. از سوی دیگر، دانشمندان داده از فناوری برای کار با دادههای کسبوکار استفاده میکنند. آنها ممکن است برنامهنویسی کنند، از تکنیکهای یادگیری ماشین برای ایجاد مدلها استفاده کنند و الگوریتمهای جدید توسعه دهند.
در بسیاری از تیمها، تحلیلگران کسبوکار و دانشمندان داده با هم کار میکنند. تحلیلگران کسبوکار از خروجی دانشمندان داده برای روایت داستانی استفاده میکنند که برای کسبوکار قابل فهم باشد.
تفاوت بین علم داده و مهندسی داده چیست؟
مهندسان داده سیستمهایی را میسازند و نگهداری میکنند که به دانشمندان داده امکان دسترسی و تفسیر دادهها را میدهد. آنها بیشتر با فناوریهای زیربنایی سروکار دارند.
وظایف مهندسان داده معمولاً شامل ایجاد مدلهای داده، ساخت پایپلاینهای داده و نظارت بر فرآیندهای ETL (استخراج، تبدیل و بارگذاری) است. بسته به ساختار و اندازه سازمان، مهندسان داده ممکن است زیرساختهای مرتبط مانند ذخیرهسازی دادههای حجیم و پلتفرمهای پردازشی مانند Amazon S3 را نیز مدیریت کنند.
دانشمندان داده از دادههایی که مهندسان داده پردازش کردهاند برای ساخت و آموزش مدلهای پیشبینی استفاده میکنند و سپس نتایج را برای تصمیمگیری به تحلیلگران ارائه میدهند.
تفاوت بین علم داده و یادگیری ماشین چیست؟
یادگیری ماشین علمی است که به آموزش ماشینها برای تحلیل و یادگیری از دادهها مانند انسان میپردازد. این یکی از روشهای مورد استفاده در پروژههای علم داده برای به دست آوردن بینش خودکار از دادهها است.
مهندسان یادگیری ماشین در زمینه محاسبات، الگوریتمها و مهارتهای برنامهنویسی مرتبط با روشهای یادگیری ماشین تخصص دارند. دانشمندان داده ممکن است از روشهای یادگیری ماشین بهعنوان یک ابزار استفاده کنند یا با مهندسان یادگیری ماشین برای پردازش دادهها همکاری کنند.
تفاوت بین علم داده و آمار چیست؟
آمار یک حوزه مبتنی بر ریاضیات است که به جمعآوری و تفسیر دادههای کمی میپردازد. در مقابل، علم داده یک حوزه چندرشتهای است که از روشها، فرآیندها و سیستمهای علمی برای استخراج دانش از دادهها در اشکال مختلف استفاده میکند.
دانشمندان داده از روشهای بسیاری از رشتهها، از جمله آمار، بهره میگیرند. با این حال، این دو حوزه در فرآیندها و مسائلی که بررسی میکنند با یکدیگر تفاوت دارند.
ابزارهای مختلف علم داده
AWSمجموعهای از ابزارها را برای حمایت از دانشمندان داده در سراسر جهان ارائه میدهد:
ذخیرهسازی داده (Data Storage)
Amazon Redshift: برای انبار داده، این ابزار میتواند کوئریهای پیچیده را روی دادههای ساختاریافته یا غیرساختاریافته اجرا کند.
AWS Glue: برای مدیریت و جستجوی دادهها، این ابزار به طور خودکار یک کاتالوگ یکپارچه از تمام دادهها در دیتا لیک ایجاد میکند و با افزودن متادیتا، دادهها را قابل کشف میسازد.
یادگیری ماشین (Machine Learning)
Amazon SageMaker: یک سرویس یادگیری ماشین کاملاً مدیریتشده است که بر روی Amazon EC2 اجرا میشود. این ابزار به کاربران امکان میدهد دادهها را سازماندهی کنند، مدلهای یادگیری ماشین بسازند، آموزش دهند و پیادهسازی کنند و عملیات را مقیاسبندی کنند.
تحلیل داده (Analytics)
Amazon Athena: یک سرویس کوئری تعاملی است که تحلیل دادهها را در Amazon S3 یا Glacier آسان میکند. این سرویس سریع، بدون سرور و با استفاده از کوئریهای استاندارد SQL کار میکند.
Amazon Elastic MapReduce (EMR): پردازش دادههای حجیم را با استفاده از سرورهایی مانند Spark و Hadoop انجام میدهد.
Amazon Kinesis: امکان جمعآوری و پردازش دادههای جریانی در زمان واقعی را فراهم میکند. این ابزار از جریان کلیکهای وبسایت، لاگهای برنامهها و دادههای تلهمتری دستگاههای اینترنت اشیا استفاده میکند.
Amazon OpenSearch: جستجو، تحلیل و تصویریسازی پتابایتهای داده را ممکن میسازد.
وظایف دانشمند داده چیست؟
دانشمندان داده در فرآیند علم داده از تکنیکها، ابزارها و فناوریهای متنوعی استفاده میکنند. آنها بر اساس مسئله، بهترین ترکیبها را برای دستیابی به نتایج سریعتر و دقیقتر انتخاب میکنند.
نقش و فعالیتهای روزانه یک دانشمند داده بسته به اندازه و نیازهای سازمان متفاوت است. در تیمهای بزرگ علم داده، دانشمند داده ممکن است با تحلیلگران دیگر، مهندسان، متخصصان یادگیری ماشین و آماردانان همکاری کند تا اطمینان حاصل شود که فرآیند علم داده بهطور کامل اجرا شده و اهداف کسبوکار محقق میشود.
در تیمهای کوچکتر، دانشمند داده ممکن است وظایف متعددی را بر عهده بگیرد. بسته به تجربه، مهارتها و پیشینه تحصیلی، آنها ممکن است نقشهای مختلف یا همپوشان را انجام دهند. در چنین مواردی، مسئولیتهای روزانه آنها میتواند شامل مهندسی داده، تحلیل، یادگیری ماشین و روششناسیهای اصلی علم داده باشد.
چالشهای دانشمندان داده
منابع داده متعدد
اپلیکیشنها و ابزارهای مختلف دادهها را در قالبهای گوناگون تولید میکنند. دانشمندان داده باید این دادهها را پاکسازی و آماده کنند تا سازگاری ایجاد شود. این فرآیند میتواند خستهکننده و زمانبر باشد.
درک مسئله کسبوکار
دانشمندان داده باید با چندین ذینفع و مدیر کسبوکار همکاری کنند تا مسئلهای که باید حل شود را تعریف کنند. این کار بهویژه در شرکتهای بزرگ با تیمهای متعدد که نیازهای متفاوتی دارند، چالشبرانگیز است.
حذف سوگیری (Bias)
ابزارهای یادگیری ماشین کاملاً دقیق نیستند و ممکن است به دلیل سوگیریها یا عدم قطعیت، دچار خطا شوند. سوگیری میتواند ناشی از عدم تعادل در دادههای آموزشی یا رفتار پیشبینی مدل در گروههای مختلف مانند سن یا طبقه درآمدی باشد.
برای مثال، اگر ابزار بیشتر بر اساس دادههای افراد میانسال آموزش دیده باشد، ممکن است در پیشبینیهایی که افراد جوانتر یا مسنتر را درگیر میکند، دقت کمتری داشته باشد. حوزه یادگیری ماشین فرصتی را برای شناسایی و اندازهگیری سوگیریها در دادهها و مدل فراهم میکند تا این مسائل رفع شوند.
آموزش مقدماتی Machine Learning: یادگیری مهارتهای پایهای در پردازش داده، مدلسازی، و ارزیابی با استفاده از ML.NET و سیشارپ.












دیدگاه کاربران