
همه ما با استفاده از نقشه برای پیداکردن مسیر در شهر یا جستجو برای یکخانه خاص، آشنایی داریم. XPath، مثل یک نقشه دیجیتال برای دادههاست. این ابزار قدرتمند به ما اجازه میدهد تا با ساختار یک سند XML یا HTML، آشنا شویم و مسیر ما را به اطلاعاتی که نیاز داریم، پیدا کنیم. اما چرا XPath برای یادگیری ماشین اهمیت دارد؟ این مقاله تلاش میکند تا پاسخ به این سؤال را به شکلی ساده و قابلفهم ارائه دهد.
XPath، کلیدی برای "دیدن" داده
ما در یادگیری ماشین به دادهها نیاز داریم، ولی این دادهها در فرمتهای مختلفی هستند. بعضی از آنها ساختاریافته هستند، مانند جداول SQL، و بعضی دیگر ساختار نیافته، مانند متون طبیعی. XML و HTML از این فرمتهای ساختاریافته هستند که برای نگهداری و انتقال دادهها بسیار مفید هستند. XPath به ما کمک میکند تا در این فضای دادهها "بگردیم" و اطلاعات موردنظرمان را پیدا کنیم.
چگونگی کشف XPath یک عنصر در وب
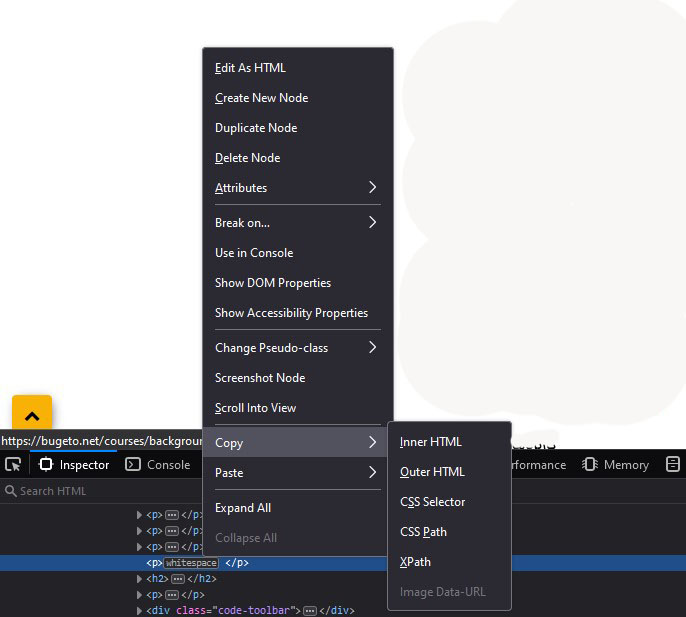
XPath یکی از راههای قدرتمند و مؤثر برای پیداکردن عناصر در یک صفحه وب است. اما چگونه میتوانیم XPath یک عنصر را به دست آوریم؟ برای این کار، میتوانیم از ابزارهای توسعهدهنده مرورگرها مانند Chrome، Firefox یا Edge استفاده کنیم. در زیر، مراحل بهدستآوردن XPath یک عنصر با استفاده از ابزار توسعهدهنده Chrome را مشاهده خواهید کرد:
1. باز کردن ابزار توسعهدهنده: ابتدا صفحه موردنظر را در مرورگر Chrome باز کنید. سپس با کلیک راست کردن بر روی عنصر موردنظر و انتخاب گزینه Inspect یا بازرسی، ابزار توسعهدهنده را باز کنید. این کار باعث میشود که کد HTML صفحه در پنجره جداگانهای باز شود و عنصری که روی آن کلیک کردهاید، برجسته شود.
2. یافتن XPath: با کلیک راست بر روی کد HTML عنصر موردنظر در ابزار توسعهدهنده، یک منو باز میشود. از این منو، گزینه Copy یا کپی را انتخاب کنید و سپس Copy XPath یا کپی XPath را انتخاب کنید. حالا XPath این عنصر در کلیپ بورد شما کپی شده است و میتوانید آن را در کد برنامه خود استفاده کنید.
با این روش، شما میتوانید بهسرعت و بادقت XPath عناصر مختلف را در یک صفحه وب به دست آورید. همچنین لازم به ذکر است که XPath بهدستآمده بستگی به ساختار صفحه وب دارد و اگر ساختار صفحه تغییر کند، XPath ممکن است نیاز به بهروزرسانی داشته باشد.
مثالهای کاربردی XPath در HTML
بیایید به مثال زیر نگاه کنیم. در اینجا یک ساختار HTML ساده داریم:
<html>
<body>
<div id="main">
<h1>Title</h1>
<p class="content">This is the main content.</p>
</div>
<div id="footer">
<p class="content">This is the footer content.</p>
</div>
</body>
</html>در این مثال، XPath میتواند به ما کمک کند تا عناصر خاصی را در سند HTML پیدا کنیم. به مثالهای زیر توجه کنید:
• برای انتخاب تگ h1 در داخل div با id برابر main، میتوانیم از XPath زیر استفاده کنیم:
//div[@id='main']/h1 این XPath، h1 را از داخل div با id برابر main انتخاب میکند.
• برای انتخاب تمام عناصر p که دارای کلاس content هستند، میتوانیم از XPath زیر استفاده کنیم:
//p[@class='content'] این XPath، هر تگ p را که دارای ویژگی class با مقدار content است، انتخاب میکند.
XPath، مانند یک نقشه برای دادههاست که به ما میگوید که چگونه میتوانیم به اطلاعاتی که ما نیاز داریم، برسیم. با فراگیری XPath، شما میتوانید به طور مؤثری دادههای خود را از سندهای XML یا HTML استخراج کنید که این موضوع برای یادگیری ماشین بسیار کلیدی است.
بهکارگیری XPath در#C
برای استفاده از XPath در C#، ابتدا باید یک سند XML یا HTML را بارگذاری کنیم. برای این کار، کتابخانه HtmlAgilityPack را میتوانیم استفاده کنیم. سپس با استفاده از روش SelectNodes و یا SelectSingleNode، میتوانیم عبارات XPath را اجرا کنیم.
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.Load("myfile.html");
foreach(HtmlNode link in doc.DocumentNode.SelectNodes("//a[@href]"))
{
HtmlAttribute att = link["href"];
Console.WriteLine(att.Value);
}در این مثال، ما یک سند HTML را بارگذاری میکنیم و سپس همه لینکهایی را که دارای ویژگی href هستند را انتخاب میکنیم.
کاربردهای XPath در یادگیری ماشین
در دنیای یادگیری ماشین، XPath میتواند بهعنوان یک ابزار قدرتمند برای جمعآوری و پردازش دادهها عمل کند. برای مثال، ما میتوانیم با استفاده از XPath دادههایی که موردنیاز برای تغذیه مدلهای یادگیری ماشینمان است را از صفحات وب جمعآوری کنیم.
XPath میتواند به ما کمک کند تا اطلاعات موردنظرمان را از میان میلیونها صفحه وب بهسرعت پیدا کنیم. این قابلیت، XPath را یکی از ابزارهای کلیدی برای دستیابی به اطلاعات موردنظر در دنیای پر از داده که در حال حاضر در آن زندگی میکنیم، میکند.
بهخاطر داشته باشید، XPath فقط یک ابزار است. این به ما کمک میکند تا دادهها را ببینیم و با آنها کار کنیم. اما همانند هر ابزار دیگری، موفقیت ما در استفاده از آن، به درک ما از آن و توانایی ما در استفاده از آن در موقعیتهای مناسب بستگی دارد. پس بیایید این مهارت را فراگرفته و به بهبود دادههای ما برای یادگیری ماشین بپردازیم.











دیدگاه کاربران