
Power BI یک راهکار تحلیل کسبوکار است که توسط مایکروسافت توسعه داده شده و به کاربران امکان میدهد دادههای خود را مصورسازی کرده و بینشهای حاصل را در سراسر سازمان خود به اشتراک بگذارند یا آنها را در برنامههای خود جایگذاری کنند. Power BI انواع مختلفی از ابزارهای مصورسازی مانند چارتها، نمودارها و عقربهها (gauges) را ارائه میدهد تا به کاربران در ایجاد گزارش از دادههایشان کمک کند. اخیراً، Power BI از یادگیری ماشین برای سادهسازی وظایف پیچیده برای کاربران خود استفاده می کند تا همهٔ افراد در سازمانها بتوانند از قدرت هوش مصنوعی (AI) برای تصمیمگیریهای بهتر استفاده کنند. در فوریهٔ ۲۰۱۹، Power BI اولین ابزار مصورسازی مبتنی بر هوش مصنوعی خود را با نام Key Influencers (عوامل کلیدی تأثیرگذار) به صورت پیشنمایش عرضه کرد که در پشت صحنه از ML.NET برای تحلیل دادهها و ارائهٔ بینشها به شیوهای طبیعی استفاده میکند.
مسئلهٔ کسبوکار
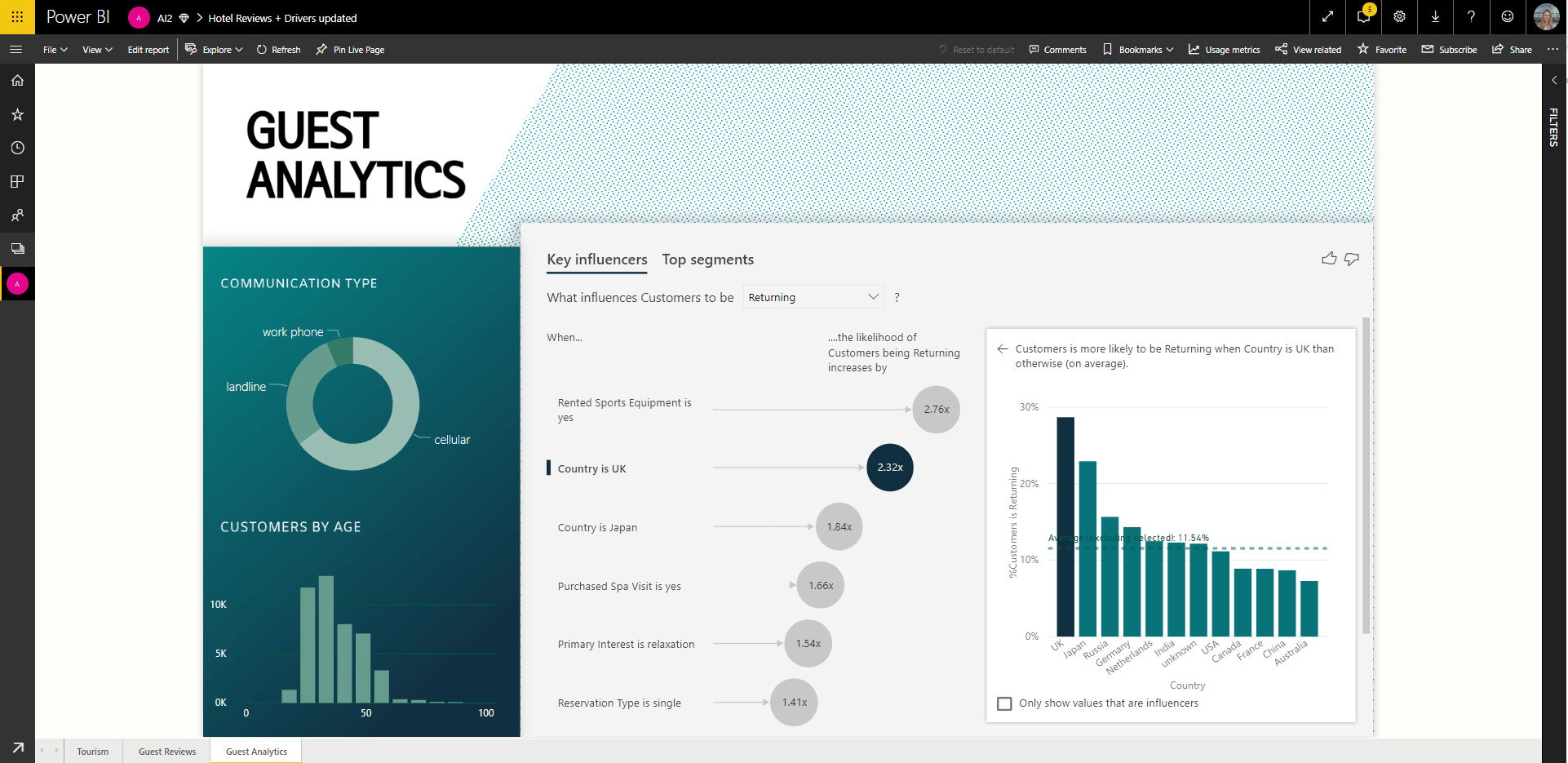
برای هر کسبوکاری، شناسایی و درک عوامل کلیدی تأثیرگذار (محرکهای اصلی عملکرد و نتایج کسبوکار) و بخشهای مشتریان (customer segments) برای اتخاذ تصمیمات استراتژیک تجاری، اولویتبندی تغییرات در کسبوکار و کسب مزیت رقابتی، حیاتی است. تحلیل عوامل کلیدی تأثیرگذار میتواند نشان دهد که کدام عوامل بیشترین تأثیر را بر عملکرد کسبوکار دارند و به یک کسبوکار کمک میکند تا به سؤالاتی مانند کدام عوامل باعث میشوند مشتریان نظرات منفی دربارهٔ این سرویس ثبت کنند؟ یا چه چیزی بر افزایش قیمت مسکن تأثیر میگذارد؟ پاسخ دهد.
با این حال، این فرآیند تحلیل داده برای شناسایی عوامل کلیدی تأثیرگذار و بخشبندی مشتریان، نیازمند زمان، تلاش و تخصص زیادی است؛ این فرآیند اغلب شامل کدنویسی چندین تابع، نمونهبرداری، آزمونهای معناداری (significance tests) و رتبهبندی نتایج است. بنابراین، Power BI به یک راهکار یادگیری ماشین روی آورد تا کاربران خود را قادر سازد فرآیند کسب بینشهای معنادار را تسریع بخشند و بتوانند تحلیلهای آماری را بدون نیاز به صرف زمان برای نوشتن کدهای پیچیده انجام دهند.
Key Influencers و ML.NET
Power BI ابزار مصورسازی Key Influencers را به عنوان یک راهکار یادگیری ماشین ایجاد کرد تا به کسبوکارها امکان دهد از هوش مصنوعی بهره ببرند، دادههای خود را در زمان کمتری تحلیل کنند و تصمیمات کلیدی کسبوکار را سریعتر اتخاذ نمایند. به عبارت دیگر، کاربران میتوانند با استفاده از Key Influencers زمان کمتری را صرف تحلیل دادهها کرده و زمان بیشتری را به اقدام بر اساس بینشهای بهدستآمده از این ابزار مصورسازی مبتنی بر هوش مصنوعی اختصاص دهند.
هنگامی که کاربر یک شاخص کلیدی عملکرد (KPI) را برای تحلیل انتخاب میکند (به عنوان مثال، نرخ حفظ مشتری، نرخ کلیک و غیره)، ابزار مصورسازی Key Influencers از الگوریتمهای یادگیری ماشین ارائهشده توسط ML.NET استفاده میکند تا مشخص کند چه عواملی بیشترین اهمیت را در پیشبرد سنجهها (metrics) دارند و همچنین بخشهای (segments) جالب توجه را برای بررسی بیشتر پیدا کند. Key Influencers دادههای کاربر را تحلیل کرده، عوامل مهم را رتبهبندی میکند، اهمیت نسبی این عوامل را با هم مقایسه کرده و آنها را به عنوان عوامل کلیدی تأثیرگذار و بخشهای برتر برای هر دو نوع سنجههای دستهای (categorical) و عددی (numeric) نمایش میدهد.
معماری راهکار
Power BI در چندین شکل عرضه میشود. ابزار مصورسازی Key Influencers در نسخههای موبایل، دسکتاپ، سرویس اشتراکی و سرویس پریمیوم پشتیبانی میشود.
زمانی که کاربر ستونهایی را به بخش بصری Key Influencer اضافه میکند، جریانی آغاز میشود که در آن دادههای آموزشی (training data) به Analysis Services (موتور پایگاه دادهٔ پشت Power BI) ارسال میشوند. Analysis Services از ML.NET برای آموزش مدلهای یادگیری ماشین استفاده کرده و نتایج بازگردانده میشوند. بنابراین، مدل هر بار که کاربر ویژگیهای (features) انتخابشده را بهروزرسانی میکند، آموزش میبیند. هدف کلی این است که تحلیل در عرض چند ثانیه انجام شود تا یک تجربهٔ تعاملی (interactive experience) فراهم گردد.
جریان کلی در ادامه نشان داده شده است:
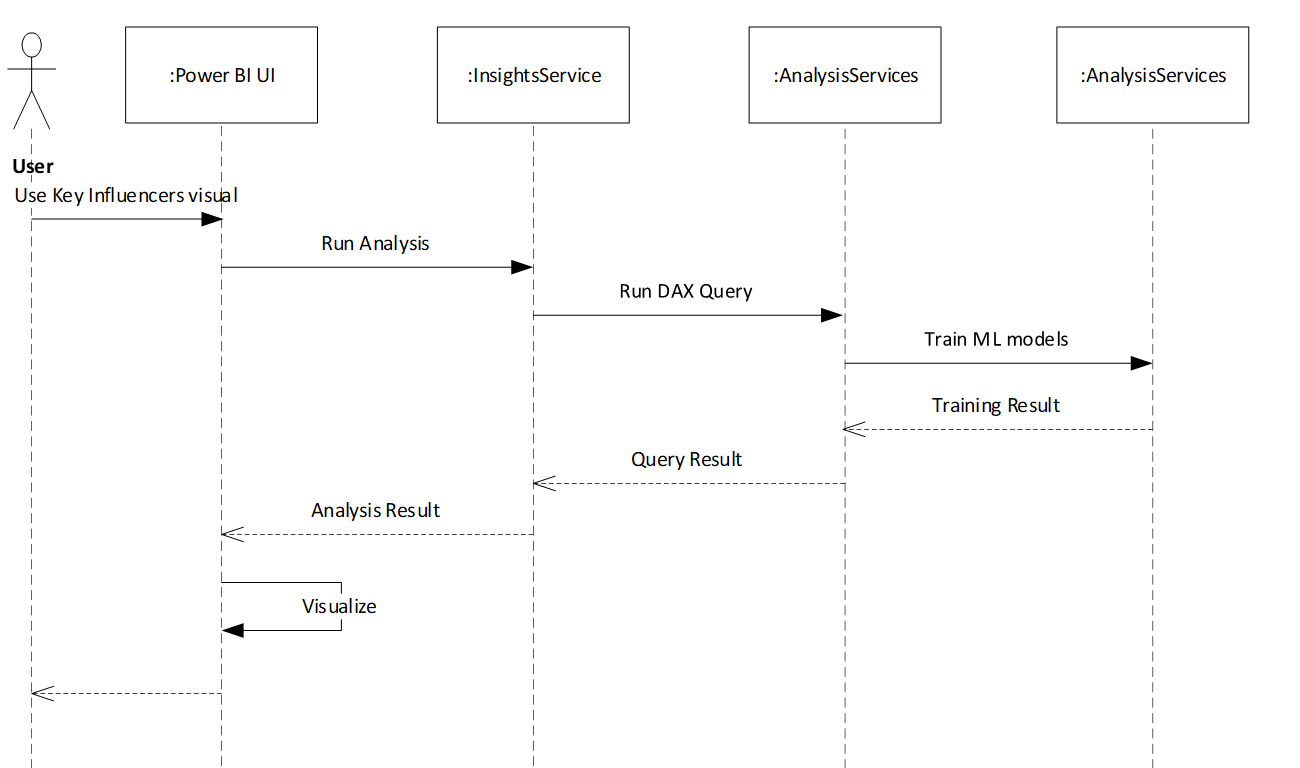
ML.NET به عنوان یک کتابخانهٔ .NET استفاده میشود و یا به صورت محلی و یا در cloud اجرا میگردد. مجموعه دادهها (Datasets) در Power BI در یک فرمت باینری مختص Analysis Services ذخیره میشوند.
عوامل کلیدی تأثیرگذار دستهای
سنجههای دستهای (Categorical metrics) میتوانند مواردی مانند امتیازدهیها یا رتبهبندیها را شامل شوند. در مثال زیر، سنجه Rating است و ابزار مصورسازی تشخیص داده که «نقش در سازمان مشتری است» (Role in Org is consumer) مهمترین عامل منحصربهفردی است که بر احتمال یک امتیاز پایین تأثیر میگذارد. این ابزار مصورسازی اطلاعات بیشتری را در پنل سمت راست نمایش میدهد، مانند:
- ۱۴.۹۳٪ از مشتریان امتیاز پایینی میدهند.
- به طور متوسط، سایر نقشها در ۵.۷۸٪ مواقع امتیاز پایینی میدهند.
- مشتریان ۲.۵۷ برابر بیشتر از سایر نقشها احتمال دارد امتیاز پایینی بدهند.
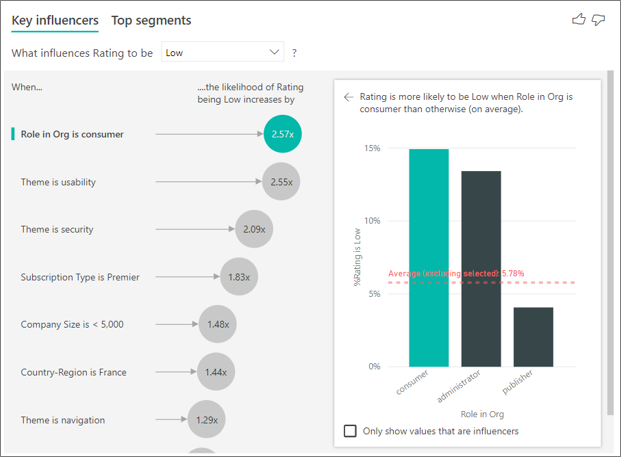
Key Influencers از ML.NET برای اجرای رگرسیون لجستیک (logistic regression) برای سنجههای دستهای استفاده میکند. این فرآیند با بهرهگیری از تبدیلهای دادهٔ One-hot encoding، جایگزینی مقادیر گمشده (Replace missing value) و نرمالسازی میانگین و واریانس (Normalize mean variance) و همچنین الگوریتم L-BFGS Logistic Regression انجام میشود. در این حالت، الگوریتم به دنبال الگوها در دادهها میگردد و بررسی میکند که مشتریانی که امتیاز پایینی دادهاند چه تفاوتی با مشتریانی که امتیاز بالایی دادهاند، دارند. به عنوان مثال، ممکن است متوجه شود مشتریانی که تیکتهای پشتیبانی بیشتری دارند، درصد بیشتری از امتیازات پایین را نسبت به مشتریانی با تیکتهای پشتیبانی کم یا بدون تیکت، ثبت میکنند.
عوامل کلیدی تأثیرگذار عددی
سنجههای عددی (Numeric metrics) میتوانند مواردی مانند قیمت یا آمار فروش را شامل شوند. در مثال زیر، سنجه قیمت مسکن (House Price) است و ابزار مصورسازی تشخیص داده که «کیفیت آشپزخانه عالی است» (Kitchen Quality is Excellent) مهمترین عامل منحصربهفردی است که بر احتمال افزایش قیمت مسکن تأثیر میگذارد.
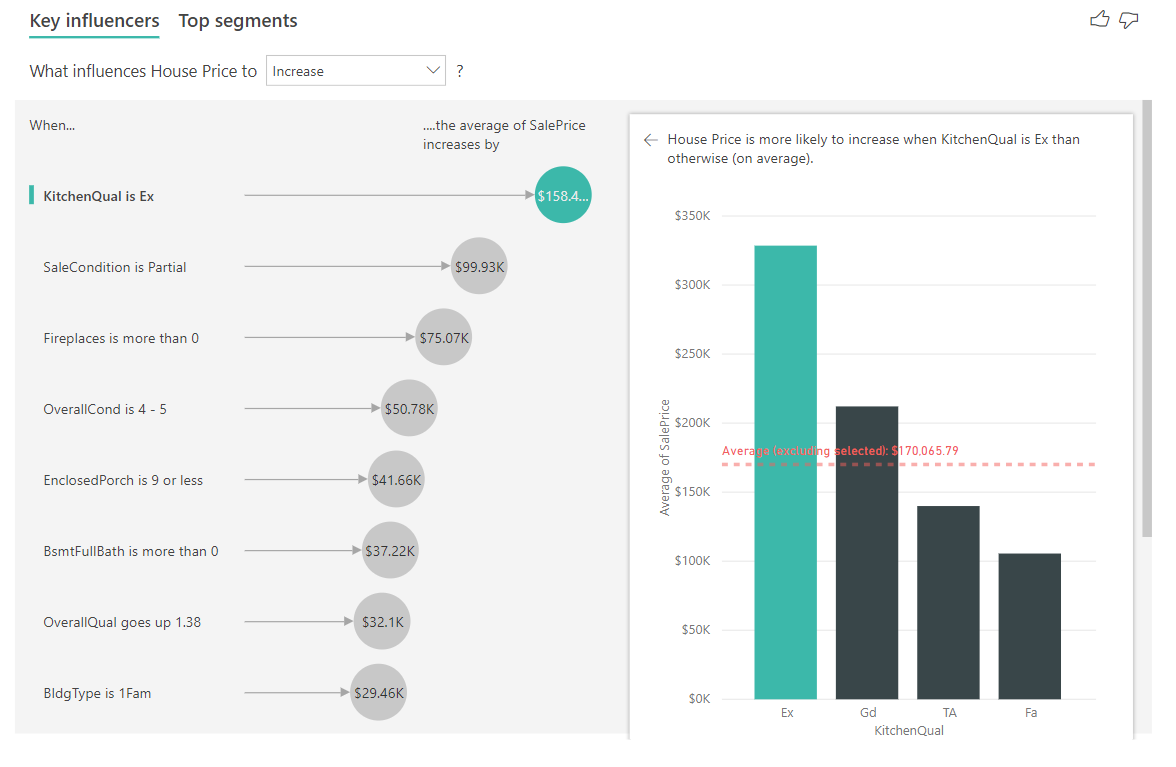
Key Influencers از ML.NET برای اجرای رگرسیون خطی (linear regression) استفاده میکند و از همان تبدیلهای دادهای که برای عوامل کلیدی تأثیرگذار دستهای به کار رفته بود، به همراه الگوریتم رگرسیون SDCA بهره میبرد. در این حالت، الگوریتم بررسی میکند که قیمت مسکن چگونه بر اساس عوامل توضیحی (explanatory factors) مانند تعداد اتاق خواب یا متراژ تغییر میکند. در این مثال خاص، تأثیر داشتن یک آشپزخانهٔ عالی بر قیمت مسکن را بررسی میکند.
محاسبهٔ بخشهای برتر
بخش Top Segments گروههای اصلی را نشان میدهد که در مقدار سنجهٔ انتخابشده نقش دارند. یک segment از ترکیبی از مقادیر تشکیل شده است. به عنوان مثال، بخش زیر شامل افرادی است که مشتری یا مدیر سیستم هستند، بیش از ۴ تیکت پشتیبانی داشتهاند و بیش از ۲۹ ماه مشتری بودهاند. ۷۴.۳٪ از مشتریان در این بخش امتیاز پایینی دادهاند، در حالی که مشتری متوسط در ۱۱.۷٪ مواقع امتیاز پایین ثبت کرده است.
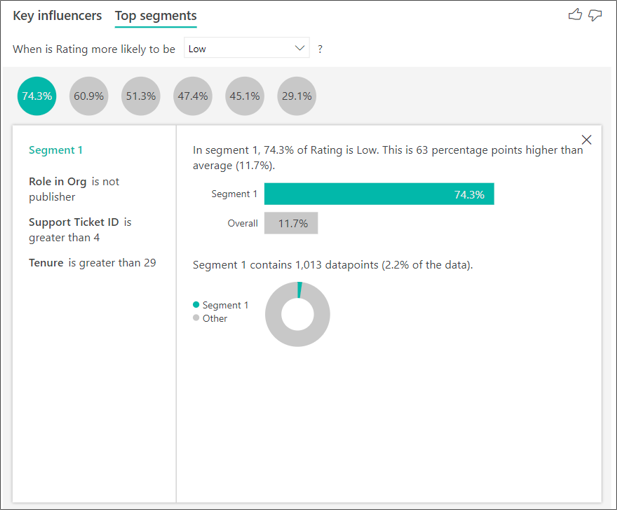
Top Segments از ML.NET برای اجرای یک درخت تصمیم (decision tree)، با استفاده از الگوریتمهای Fast tree (برای دادههای دستهای و عددی)، جهت یافتن زیرگروههای جالب توجه استفاده میکند. هدف این است که به زیرگروهی از نقاط داده برسیم که در سنجهٔ مورد نظر مقدار نسبتاً بالایی داشته باشند. این میتواند شامل مشتریان با امتیازات پایین یا خانههایی با قیمتهای بالا باشد.
الگوریتم هر عامل توضیحی را در نظر گرفته و سعی میکند تشخیص دهد کدام عامل بهترین split را ایجاد میکند. پس از اینکه درخت تصمیم یک تقسیم انجام داد، زیرگروه داده را برداشته و بهترین تقسیم بعدی را برای آن داده تعیین میکند. در این مورد، زیرگروه مشتریانی هستند که در مورد امنیت نظر دادهاند. پس از هر تقسیم، الگوریتم همچنین بررسی میکند که آیا نقاط دادهٔ کافی برای این گروه وجود دارد تا به اندازهٔ کافی نماینده (representative) باشد و بتوان از آن یک الگو استنباط کرد، یا اینکه یک ناهنجاری (anomaly) در دادههاست و یک بخش واقعی نیست. پس از پایان اجرای درخت تصمیم، تمام تقسیمها، مانند نظرات امنیتی و شرکتهای بزرگ، را در نظر گرفته و بخشها را ایجاد میکند.
Power BI از ML.NET استفاده میکند تا به مشتریان خود کمک کند به راحتی عوامل کلیدی تأثیرگذار را در کسبوکارهایشان شناسایی کنند، در نتیجه در وقت و تلاش آنها صرفهجویی شده و به آنها امکان میدهد بر اساس تحلیلها و بینشهای تولیدشده از مدلهای ML.NET، بر ایجاد تغییرات و اتخاذ تصمیمات تجاری تمرکز کنند.


![معرفی 16 نوع از بهترین نمودار ها و گراف ها برای نمایش داده ها [+ راهنما]](https://bugeto.net/images\2023\2023-8\2023-8-15\bugeto-Charts and graphs.png)









دیدگاه کاربران