
ساختار داده چیست؟
ساختار داده روشی برای قالببندی دادهها است به گونهای که بتوان از آن در یک برنامه کامپیوتری یا سیستم دیگر استفاده کرد. ساختارهای داده یکی از اجزای اساسی علوم کامپیوتر هستند، زیرا به دادههای انتزاعی شکل میدهند. به این ترتیب، آنها به کاربران و سیستمها اجازه میدهند تا دادهها را به صورت کارآمد سازماندهی، پردازش و ذخیره کنند.
ساختارهای داده انواع دادههای اولیه مانند اعداد، کاراکترها، مقادیر بولین و اعداد صحیح را در یک قالب منسجم ترکیب میکنند. به تنهایی، هر کدام از این نوع دادههای اولیه فقط یک مقدار واحد دارند. اما وقتی در یک ساختار داده ترکیب شوند، عملیات سطح بالاتری مانند مرتبسازی، جستجو، درج و حذف را امکانپذیر میکنند.
در علوم کامپیوتر و برنامهنویسی، یک ساختار داده ممکن است برای ذخیره دادهها انتخاب یا طراحی شود تا بتوان آن را با الگوریتمهای مختلف استفاده کرد. این ترکیب معمولاً به نام «ساختار دادهها و الگوریتمها» (DSA) شناخته میشود. در برخی موارد، عملیات پایهای الگوریتمها به طور مستقیم با طراحی ساختار داده مرتبط هستند. هر ساختار داده شامل اطلاعاتی درباره مقادیر دادهها، روابط بین دادهها و در برخی موارد، توابعی است که میتوانند بر روی دادهها اعمال شوند.
به عنوان مثال، فرض کنید یک تیم فروش میخواهد آمار فروش روزانه را پیگیری کند. به جای ثبت جداگانه هر نقطه داده، این تیم میتواند این دادهها را در نوعی ساختار داده به نام «آرایه» ذخیره کند. (برای اطلاعات بیشتر، به بخش «انواع ساختارهای داده» مراجعه کنید.)
در زبان پایتون، این آرایه ممکن است به این صورت باشد:
daily_sales = [500, 800, 600, 1200, 950]استفاده از آرایه به تیم اجازه میدهد تا تمام این دادهها را در کنار هم نگه دارد، نقاط داده را به راحتی در زمان نیاز بازیابی کند و عملیاتهایی را هم بر روی عناصر فردی و هم بر روی کل آرایه انجام دهد.
برنامهنویسان کامپیوتر برای ساخت برنامههای کاربردی کارآمد به ساختارهای داده تکیه میکنند. در زمینههای علوم کامپیوتر و علم داده، ساختارهای داده برای سیستمعاملها، پایگاههای داده، وبسایتها، گرافیک، تحلیل دادهها، بلاکچین، برنامههای یادگیری ماشین (ML) و موارد دیگر ضروری هستند.
از آنجا که ساختارهای داده برای نوشتن کدهای کارآمد حیاتی هستند، معمولاً یکی از اولین درسهایی هستند که به مبتدیان برنامهنویسی آموزش داده میشوند. همچنین، این موضوع یکی از سوالات رایج در مصاحبههای شغلی برنامهنویسان کامپیوتر است.
چرا ساختارهای داده مهم هستند؟
ساختارهای داده مهم هستند زیرا پردازش مجموعههای بزرگ و پیچیده اطلاعات را برای کامپیوترها آسانتر میکنند. با سازماندهی منطقی عناصر داده، ساختارهای داده کارایی کد کامپیوتر را افزایش میدهند و درک کد را سادهتر میکنند.
نوعهای پایهای داده، مانند اعداد صحیح یا مقادیر اعشاری که در بیشتر زبانهای برنامهنویسی موجود هستند، معمولاً برای نمایش هدف منطقی پردازش و استفاده از دادهها کافی نیستند. اما برنامههایی که دادهها را دریافت، پردازش و تولید میکنند، باید بدانند که دادهها چگونه باید سازماندهی شوند تا پردازش آنها سادهتر شود.
ساختارهای داده عناصر داده را به شکلی منطقی کنار هم قرار میدهند و استفاده مؤثر، ذخیرهسازی پایدار و اشتراکگذاری دادهها را تسهیل میکنند. این ساختارها یک مدل رسمی ارائه میدهند که نحوه سازماندهی عناصر داده را توضیح میدهد.
ساختارهای داده و الگوریتمها (DSA)
برنامهنویسان از ساختارهای داده برای بهبود سرعت و کارایی الگوریتمها استفاده میکنند. الگوریتمها مجموعهای از دستورالعملها برای انجام یک کار محاسباتی هستند. در برنامهنویسی کامپیوتری، این ترکیب به نام "DSA" که مخفف "Data Structures and Algorithms" است، شناخته میشود. DSA به برنامهنویسان کمک میکند تا دو چالش اصلی پیچیدگی زمانی و پیچیدگی فضایی را برطرف کنند. الگوریتم برنامهنویسی چیست؟
پیچیدگی زمانی:
معیاری است که نشان میدهد یک الگوریتم بر اساس مقدار ورودی چقدر زمان برای تکمیل یک کار نیاز دارد.
پیچیدگی فضایی:
معیاری است که نشان میدهد یک الگوریتم بر اساس مقدار ورودی چقدر حافظه استفاده میکند.
با استفاده از متریک ریاضی به نام Big O notation، برنامهنویسان میتوانند پیچیدگی زمانی و فضایی را اندازهگیری کنند. سپس میتوانند تعیین کنند که کدام ساختارهای داده و الگوریتمها برای یک وظیفه خاص سریعترین زمان اجرا و بیشترین کارایی فضایی را فراهم میکنند.
برنامهنویسی پویا (Dynamic Programming)
ساختارهای داده نقش مهمی در برنامهنویسی پویا ایفا میکنند، که یک تکنیک برای حل سریع مسائل پیچیده است.
برنامهنویسی پویا از بازگشت (Recursion) برای تقسیم یک مسئله به اجزای کوچکتر استفاده میکند. سپس، برنامه راهحلهایی برای این اجزا پیدا کرده و این زیرراهحلها را به یک راهحل کامل برای مسئله اصلی تبدیل میکند.
ساختارهای داده برنامهنویسی پویا را ممکن میسازند، زیرا به برنامه راهی برای ذخیره و بازیابی هر زیرراهحل میدهند و عناصر داده را به صورت منطقی در طول فرآیند سازماندهی میکنند.
برای مثال، مقادیر محاسبهشده میتوانند در یک آرایه ذخیره شوند. به جای محاسبه دوباره این مقادیر هنگام فرمولبندی راهحل کامل، برنامه میتواند آنها را از آرایه بازیابی کند.
با این قابلیتها، برنامهنویسان میتوانند در زمان صرفهجویی کرده و مسائل را با کارایی بیشتری حل کنند
ویژگیهای ساختارهای داده
ساختارهای داده معمولاً بر اساس ویژگیهای زیر دستهبندی میشوند:
خطی یا غیرخطی:
این ویژگی تعیین میکند که آیا دادهها به صورت ترتیبی (مانند آرایه) سازماندهی شدهاند یا به صورت نامرتب (مانند گراف).
همگن یا ناهمگن:
این ویژگی مشخص میکند که آیا همه عناصر داده در یک مجموعه از یک نوع هستند (مانند مجموعهای از عناصر در یک آرایه) یا از انواع مختلف (مانند یک نوع داده انتزاعی که به صورت ساختار در C یا به صورت کلاس در جاوا تعریف شده است).
ایستا و پویا:
این ویژگی به نحوه کامپایل شدن ساختارهای داده اشاره دارد. ساختارهای داده ایستا دارای اندازه، ساختار و مکان حافظه ثابت در زمان کامپایل هستند. ساختارهای داده پویا اندازه، ساختار و مکان حافظهای دارند که بسته به نیاز میتوانند تغییر کنند (کوچکتر یا بزرگتر شوند).
انواع داده
اگر ساختارهای داده، اجزای سازنده الگوریتمها و برنامههای کامپیوتری باشند، انواع داده اولیه یا پایه اجزای سازنده ساختارهای داده هستند. انواع داده پایهای معمول عبارتند از:
بولین (Boolean):
مقادیر منطقی را ذخیره میکند که یا درست (true) هستند یا غلط (false).
صحیح (Integer):
اعداد صحیح ریاضی یا شمارشی را ذخیره میکند. اندازههای مختلف اعداد صحیح، محدوده متفاوتی از مقادیر را نگه میدارند. برای مثال، یک عدد صحیح ۸ بیتی علامتدار مقادیر بین -۱۲۸ تا ۱۲۷ را نگه میدارد، و یک عدد صحیح ۳۲ بیتی بدون علامت مقادیر بین ۰ تا ۴,۲۹۴,۹۶۷,۲۹۵ را ذخیره میکند.
اعداد اعشاری (Floating-point):
نمایش فرمولی از اعداد واقعی را ذخیره میکنند.
اعداد اعشاری ثابت (Fixed-point):
در برخی زبانهای برنامهنویسی استفاده میشوند و اعداد واقعی را نگهداری میکنند اما به صورت ارقام در سمت چپ و راست ممیز مدیریت میشوند.
کاراکتر (Character):
از نمادها بر اساس نگاشت مقادیر عددی به نمادها استفاده میکند.
اشارهگرها (Pointers):
مقادیر ارجاعی هستند که به مقادیر دیگر اشاره میکنند.
رشتهها (String):
آرایهای از کاراکترها هستند که با یک کد توقف (معمولاً مقدار "0") پایان مییابند یا با استفاده از یک فیلد طول که مقدار عدد صحیح است مدیریت میشوند.`
ساختارهای داده خطی و غیرخطی
ساختارهای داده به دو دسته اصلی تقسیم میشوند: خطی و غیرخطی.
ساختارهای داده خطی
در یک ساختار داده خطی، دادهها به صورت یک خط مرتب شدهاند، به طوری که هر عنصر داده به ترتیب پشت سر هم قرار میگیرد. این نوع سازماندهی، پیمایش و دسترسی به عناصر را به ترتیب ساده میکند.
ساختارهای داده خطی به دلیل سادگی درک و پیادهسازی، به عنوان ساختارهایی ساده و قابل فهم شناخته میشوند. نمونههای رایج در این دسته شامل آرایهها، لیستهای پیوندی و صفها هستند.
ساختارهای داده غیرخطی
در یک ساختار داده غیرخطی، منطق سازماندهی به گونهای است که ترتیب دادهها به صورت خطی و متوالی نیست. برای مثال، نقاط داده میتوانند به صورت سلسلهمراتبی یا در یک شبکه به هم متصل باشند.
از آنجا که عناصر در یک ساختار غیرخطی به صورت یک خط واحد به هم متصل نیستند، نمیتوان همه عناصر را مانند ساختارهای خطی در یک مرحله پیمایش و دسترسی کرد. نمونههایی از ساختارهای داده غیرخطی شامل درختها و گرافها هستند.
انواع ساختارهای داده
ساختارهای داده مختلفی وجود دارند که برنامهنویسان بسته به سیستمی که در حال ساخت آن هستند و نیاز به کار با دادهها از آنها استفاده میکنند. ساختارهای داده رایج عبارتند از:
آرایهها (Arrays)
صفها (Queues)
پشتهها (Stacks)
لیستهای پیوندی (Linked Lists)
درختها (Trees)
گرافها (Graphs)
جدولهای هش (Hash Tables)
آرایهها (Arrays)
آرایهها یکی از ابتداییترین و پرکاربردترین انواع ساختارهای داده هستند. آنها آیتمهای دادهای از یک نوع مشابه را در مکانهای متوالی حافظه ذخیره میکنند. این ساختار امکان دسترسی و مکانیابی آسان آیتمهای مشابه را فراهم میکند. آرایه در برنامه نویسی چیست؟
کاربردها:
آرایهها معمولاً برای مرتبسازی، ذخیرهسازی، جستجو و دسترسی به دادهها استفاده میشوند. همچنین، آرایهها میتوانند به عنوان پایهای برای پیادهسازی سایر ساختارهای داده مانند صفها و پشتهها مورد استفاده قرار گیرند.
مثال:
آرایهای از امتیازات متوسط رضایت مشتریان در یک مرکز تماس ممکن است به این صورت باشد:
average_customer_score = [4, 3.5, 3.7, 4.1, 3.4, 4.9]صفها (Queues)
یک صف عملیات داده را به ترتیبی از پیش تعیینشده به نام FIFO (مخفف First In, First Out یا «اولین ورودی، اولین خروجی») انجام میدهد. این بدان معناست که اولین آیتمی که اضافه میشود، اولین آیتمی است که حذف میشود. برنامهنویسان اغلب از این ساختار داده برای ایجاد صفهای اولویتدار استفاده میکنند که شبیه به لیستهای انتظار هستند.
کاربردها:
ساختار داده صف میتواند برای تعیین آهنگ بعدی در یک لیست پخش، کاربر بعدی برای دسترسی به یک چاپگر مشترک، یا تماس بعدی برای پاسخدهی در یک مرکز تماس استفاده شود.
مثال:
مشتریانی که منتظر صحبت با نماینده مرکز تماس هستند، ممکن است در صفی به این شکل قرار گیرند:
queue = [customer 1, customer 2, customer 3]زمانی که یک نماینده در دسترس باشد، به طور خودکار به اولین مشتری در صف متصل میشود و این مشتری از لیست حذف میشود. اکنون صف به این صورت خواهد بود:
queue = [customer 2, customer 3]پشتهها (Stacks)
مشابه صفها، ساختار داده پشته نیز عملیات داده را به ترتیبی از پیش تعیینشده انجام میدهد. اما برخلاف FIFO در صفها، پشتهها از قالب LIFO استفاده میکنند که مخفف Last In, First Out یا «آخرین ورودی، اولین خروجی» است. به این معنا که آخرین آیتمی که اضافه میشود، اولین آیتمی است که حذف میشود.
کاربردها:
پشتهها میتوانند برای اطمینان از باز و بسته شدن صحیح پرانتزها یا تگها در کدهای کامپیوتری، ردیابی تاریخچه اخیر مرورگر یا لغو عملیات اخیر در یک برنامه استفاده شوند.
مثال:
بسیاری از برنامهها از پشتهها برای ردیابی اقدامات کاربران استفاده میکنند تا به راحتی قابل لغو باشند. برای مثال، یک ویرایشگر متن ممکن است پشتهای مانند این داشته باشد:
recent_actions = [typing '.', space, typing 'T']وقتی کاربر دکمه «undo» را فشار میدهد، آخرین اقدام در پشته—«تایپ کردن 'T'»—لغو میشود. حالا پشته به این صورت خواهد بود:
recent_actions = [typing '.', space]لیستهای پیوندی (Linked Lists)
لیستهای پیوندی دادهها را به صورت خطی ذخیره میکنند، به طوری که هر آیتم به آیتم بعدی در لیست متصل است. این ساختار امکان افزودن آیتمهای جدید یا حذف آیتمهای موجود را بدون نیاز به جابجایی کل مجموعه دادهها فراهم میکند.
کاربردها:
لیستهای پیوندی اغلب برای درج و حذف مکرر در سناریوهایی مانند تاریخچه مرورگر وب، لیستهای پخش در پخشکنندههای رسانهای و عملیات Undo یا Redo در برنامهها استفاده میشوند.
مثال:
یک نسخه ساده از لیست پیوندی ویدیوها در یک پخشکننده رسانه ممکن است به این صورت باشد:
ویدیو 1 – ویدیو 2 – ویدیو 3هر آیتم در لیست به آیتم بعدی اشاره میکند، بنابراین وقتی ویدیو 1 تمام میشود، پخشکننده رسانه به طور خودکار ویدیو 2 را شروع میکند.
درختها (Trees)
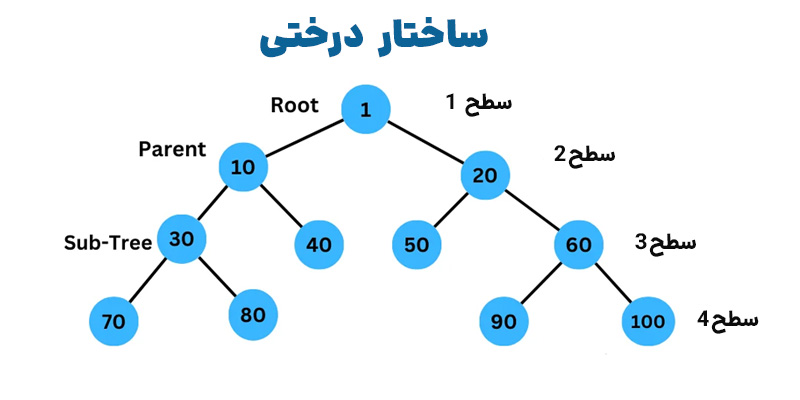
ساختار داده درخت، که گاهی به آن درخت پیشوندی نیز گفته میشود، برای ایجاد روابط سلسلهمراتبی بین عناصر داده مفید است. یک گره والد در بالای ساختار درخت قرار دارد و گرههای فرزند از آن در سطوح بعدی منشعب میشوند.
انواع مختلفی از درختها، مانند درختهای جستجوی دودویی (Binary Search Trees)، درختهای AVL و درختهای B، ویژگیها و عملکردهای متفاوتی دارند. به عنوان مثال، در یک درخت جستجوی دودویی، هر گره حداکثر ۲ فرزند دارد. این ساختار از جستجوی سریع مجموعه دادهها پشتیبانی میکند.
کاربردها:
درختها اغلب برای نمایش سلسلهمراتبها در نقشههای سازمانی، سیستمهای فایل، سیستمهای نام دامنه (DNS)، ایندکسگذاری پایگاه داده و درختهای تصمیمگیری در برنامههای یادگیری ماشین استفاده میشوند.
مثال:
(در ادامه مثالها و کاربردهای عملیتر بیان میشود.)
گرافها (Graphs)
ساختار داده گراف، روابط بین اشیاء مختلف را با استفاده از راسها (Vertices) و یالها (Edges) سازماندهی میکند. راسها نقاط دادهای هستند که با نقاط (دایرهها) نشان داده میشوند، و یالها خطوطی هستند که راسها را به هم متصل میکنند.
برای مثال:
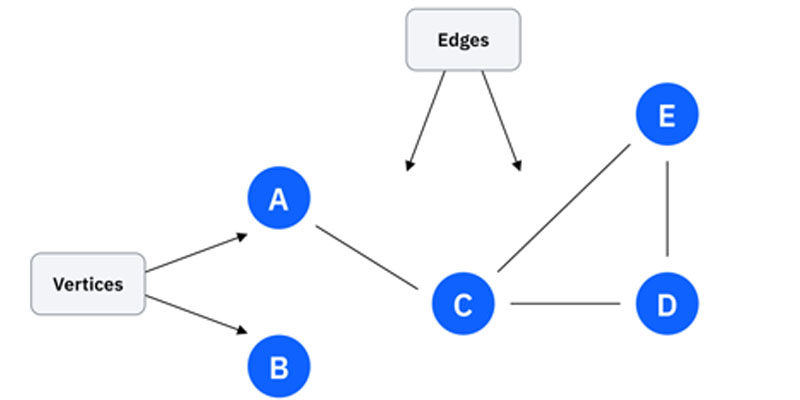
در یک نقشه، شهرها راسها هستند و جادههایی که آنها را به هم متصل میکنند، یالها هستند.
در فیسبوک، کاربران راسها هستند و روابط دوستی که آنها را به هم متصل میکنند، یالها هستند.
کاربردها:
ساختار داده گراف اغلب در کنار الگوریتمهای جستجو استفاده میشود که به دنبال دادهها در شبکههای پیچیده از روابط هستند. مثالهای رایج شامل:
جستجوی عرضی (Breadth-First Search): که دادهها را سطح به سطح جستجو میکند.
جستجوی عمقی (Depth-First Search): که به عمق سطوح مختلف دادهها نفوذ میکند تا اطلاعات مورد نظر را پیدا کند.
مثال:
(در ادامه میتوان نمونههای عملی بیشتری ارائه داد.)
هش (Hash)
ساختار داده هش، که گاهی به آن جدول هش (Hash Table) یا هش مپ (Hash Map) گفته میشود، از یک تابع هش (Hash Function) برای ذخیره مقادیر داده استفاده میکند. این تابع هش یک کلید دیجیتال منحصربهفرد ایجاد میکند که به مکان یک مقدار داده خاص در حافظه اشاره دارد.
جدول هش شامل یک ایندکس قابل جستجو از هر جفت کلید و مقدار داده است که امکان دسترسی، افزودن و حذف سریع دادهها از جدول را فراهم میکند.
کاربردها:
ساختار داده هش میتواند برای جستجوی سریع دادهها در دفترچههای تلفن، فرهنگلغتها و فهرست کارکنان استفاده شود. همچنین میتوان از آن برای ایندکسگذاری پایگاه دادهها، ذخیره رمزهای عبور و توزیع بار در سیستمهای فناوری اطلاعات (Load Balancing) استفاده کرد.
مثال:
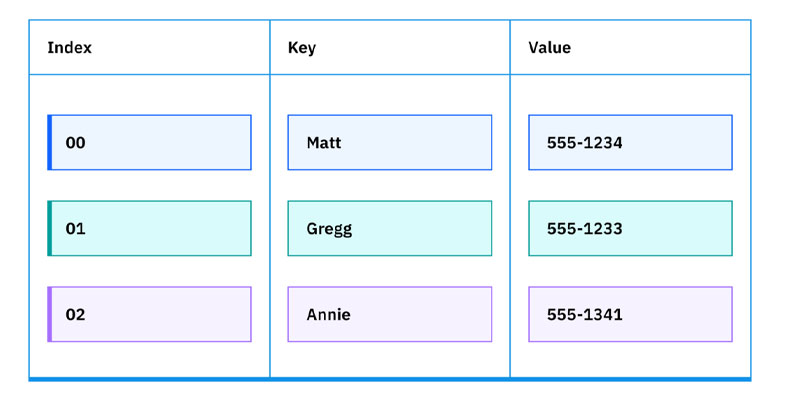
نسخهای ساده از یک جدول هش که لیست مخاطبین یک تلفن هوشمند را سازماندهی میکند ممکن است به این صورت باشد:
تابع هش هر کلید را به ایندکس مناسب نگاشت میکند. بنابراین، زمانی که کاربر یک کلید (مانند نام مخاطب) وارد میکند، جدول هش مقدار مرتبط با آن ایندکس (مانند شماره تماس) را بازمیگرداند
موارد استفاده از ساختارهای داده
ساختارهای داده در طراحی برنامههای نرمافزاری بسیار حیاتی هستند، زیرا آنها اشکال ملموس نوع داده انتزاعی (Abstract Data Type) را پیادهسازی میکنند.
نوع داده انتزاعی یک مدل ریاضی است که رفتار یک نوع داده و عملیاتی که میتوان روی آن انجام داد را طبقهبندی میکند. برای مثال، نوع داده انتزاعی صف (Queue) رفتار صف را تعریف میکند (بر اساس اصل FIFO یا «اولین ورودی، اولین خروجی»). ساختار داده صف روشی را برای قالببندی دادهها به شکل صف فراهم میکند، به طوری که یک برنامه کامپیوتری بتواند اصل FIFO را روی آن دادهها اعمال کند.
بسیاری از زبانهای برنامهنویسی مانند Python، Java و JavaScript شامل ساختارهای داده داخلی هستند که به توسعهدهندگان کمک میکنند کارآمدتر کار کنند.
موارد استفاده رایج از ساختارهای داده در برنامههای کامپیوتری:
ذخیرهسازی و سازماندهی دادهها:
استفاده از ساختارهایی مانند آرایهها، لیستهای پیوندی و درختها برای مدیریت دادهها.
ساختارهای داده میتوانند دادهها را به صورت منطقی و کارآمد ذخیره کنند و با سطح بالایی از پایداری دادهها امکان دسترسی آسان به آنها را از پایگاههای داده و برنامههای دیگر فراهم کنند. همچنین، ساختارهای داده سازماندهی منطقی برای حجم زیادی از دادهها ایجاد میکنند تا مرتبسازی، نظمدهی و پردازش آنها آسانتر شود.
مثال:
یک وبسایت میتواند از لیستهای پیوندی (Linked Lists) برای ذخیره گزارش فعالیت کاربران استفاده کند. این لیستها میتوانند رویدادها را به ترتیب زمانی ثبت کنند و پیوندهای بین رویدادها تصویر کاملی از اقدامات کاربر در هر جلسه ارائه دهند.
ایندکسگذاری:
بهینهسازی دسترسی به دادهها با استفاده از ساختارهایی مانند درختهای B یا جدولهای هش.
ساختارهای داده میتوانند اطلاعات را با نگاشت مقادیر داده به آیتمهای داده مرتبط در یک پایگاه داده ایندکسگذاری کنند، که این امر یافتن و دسترسی به رکوردهای داده را آسانتر میکند.
مثال:
یک وبسایت تجارت الکترونیک میتواند از جدول هش (Hash Table) برای ایندکسگذاری محصولات در دستهبندیها استفاده کند. هنگامی که کاربر میخواهد فقط یک دسته خاص را مشاهده کند، وبسایت میتواند از مقدار هش برای بازیابی سریع تمام محصولات مرتبط استفاده کند، به جای جستجو در کل پایگاه داده.
تبادل دادهها:
سازماندهی اطلاعاتی که بین برنامهها به اشتراک گذاشته میشود، مانند بستههای TCP/IP.
ساختارهای داده، دادهها را به گونهای سازماندهی میکنند که به راحتی بین برنامهها به اشتراک گذاشته شوند.
مثال:
بسیاری از برنامهها از صفها (Queues) برای مدیریت و ارسال بستهها از طریق پروتکلهایی مانند TCP/IP استفاده میکنند. صفها اطمینان حاصل میکنند که بستهها به ترتیبی که ایجاد شدهاند ارسال و دریافت میشوند
جستجو:
استفاده از الگوریتمهای جستجو با کمک ساختارهایی مانند درختهای جستجو یا گرافها برای یافتن دادهها.
با سازماندهی دادهها به گونهای که برای برنامهها و کاربران سادهتر قابل درک باشد، ساختارهای داده جستجو و یافتن دادهها را آسانتر میکنند.
مثال:
ساختارهای داده گراف (Graph Data Structures) میتوانند یافتن افراد مرتبط در سایتهای شبکههای اجتماعی را سادهتر کنند. این ساختارها روابط بین گرهها یا رأسها را ثبت میکنند. الگوریتمهای جستجو میتوانند از یک گره به گره دیگر حرکت کنند تا کاربران مرتبط را به طور کارآمد پیدا کنند.
مقیاسپذیری:
مدیریت دادهها در برنامههای کلان داده و سیستمهای توزیعشده برای حفظ عملکرد و کارایی.
ساختارهای داده از مقیاسپذیری سیستمها پشتیبانی میکنند و به برنامههای کامپیوتری کمک میکنند تا مجموعههای بزرگ داده را پردازش کنند، مسائل پیچیده را حل کنند و منابع را به طور کارآمدتری استفاده کنند.
مثال:
هم جدولهای هش و هم ساختارهای درختی میتوانند یافتن اطلاعات مرتبط در مجموعههای بزرگ داده را آسانتر کنند. به جای بررسی هر عنصر، سیستمها فقط باید از کلید مناسب استفاده کنند یا مسیر درست را در درخت دنبال کنند. این امر باعث میشود عملکرد بالا باقی بماند، زیرا سیستم نیازی به استفاده از منابع زیاد برای جستجو در حجم وسیعی از دادهها ندارد.
ساختار برای سازماندهی و دسترسی به دادهها و همچنین برای افرادی که مسئول آنها هستند حیاتی است. یادگیری نحوه ساختاردهی و مدیریت تیمهای تحلیل داده در سازمانها بسیار اهمیت دارد.

.jpg)










دیدگاه کاربران