
Databases NoSQL چیست؟
بانک های اطلاعاتی NOSQL ( مخفف NOT ONLY SQL )به شکل غیر جدولی می باشد و نحوه ذخیره سازی اطلاعات در آن نسبت با پایگاه های داده رابطه ای کاملا متفاوت است این نوع پایگاه های داده ساختار یا Schema غیر ثابتی دارند حالا این یعنی چه؟ در بانک های اطلاعاتی رابطه ای، ساختار از پیش تعیین شده ای را دارند برای مثال ما جدولی را طراحی می کنیم.
در تصویر بالا همان طور که مشاهده می کنید جدول ما دارای یک ساختار می باشد که هنگام ثبت اطلاعات باید از این Schema پیروی کرد. اما در پایگاه های داده NoSQL به این گونه نبوده و ما هر نوع ساختاری را می توانیم هنگام ثبت کنیم که به این ویژگی Dynamic Schema گفته می شود، این قابلیت باعث می شود که برنامه نویس احتیاجی به ساخت Schema ها سخت گیرانه مشخص که پیش از ایجاد پایگاه داده طراحی شده است نداشته باشد. این نوع بانک ها برای ذخیره سازی معمولا از XML یا JSON و ... استفاده می کنند.
نکته مثبت دیگر این است که این نوع بانک ها رابطه ای نیستند و همین امر باعث شده تا سرعت بالایی را به همراه داشته باشد و همچنین در مسائل Big Data که با اطلاعات بسیار زیادی رو به رو هستیم بهترین گزینه باشد. تصور غلطی که درباره ی بانک های اطلاعاتی NoSQL وجود دارد که بانک های اطلاعاتی غیر رابطه ای هستند که داده های رابطه ای را به خوبی ذخیره سازی نمی کنند این یک نظر کاملا اشتباه بوده چرا که این نوع بانک ها هم اطلاعات رابطه ای را ذخیره می کنند اما متفاوت از بانک های اطلاعاتی رابطه ای. در حقیقت، در مقایسه با پایگاه داده های SQL بسیاری از داده های مدل سازی در بانک های اطلاعاتی NoSQL آسانتر از پایگاه داده های SQL هستند زیرا داده های مرتبط نیازی به تقسیم بین جداول ندارند، مدل های داده NoSQL اجازه می دهد تا داده های مرتبط در یک ساختار داده واحد قرار بگیرند.
مختصری از تاریخچه ی Databases NoSQL
بانک های اطلاعاتی NoSQL در اواخر دهه ۲۰۰۰ پدیدار شدن زیرا هزینه های ذخیره سازی به طرز چشمگیری کاهش می یافت، با کاهش سریع هزینه های ذخیره سازی، میزان برنامه های داده مورد نیاز برای ذخیره و جستجوی اطلاعات را افزایش داد. بانک های اطلاعاتی NoSQL به توسعه دهندگان امکان می داد مقادیر زیادی از داده های بدون ساختار را ذخیره کنند و انعطاف پذیری زیادی را شامل شود.
همچنین رایانش ابری محبوبیت خود را افزایش داد و توسعه دهندگان شروع به استفاده از ابر های Public برای میزبانی برنامه ها و داده ها خود کردند آنها می خواستند این امکان را برای توزیع داده ها در چندین سرور و مناطق فراهم کنند تا برنامه های خود را به صورت انعطاف پذیر، مقیاس بندی به جای مقیاس بالا و جغرافیایی هوشمند داده های خود قرار دهند که برخی از بانک های اطلاعاتی NoSQL این قابلیت را فراهم می کردند.
SQL چیست؟
اکنون که با مفهوم بانک های اطلاعاتی NoSQL آشنا شدیم بیایید آن را به آنچه به صورت سنتی محبوب ترین پایگاه داده ها بوده است مقایسه کنیم:
بانک های اطلاعاتی رابطه ای که با SQL به آن ها دسترسی پیدا می کنید (زبان مورد استفاده در این نوع پایگاه های داده رابطه ای) هنگام تعامل با پایگاه های داده رابطه ای ، داده ها در جدول دارای ستون ها و ردیف ها ثابت ذخیره شده اند، که مخفف Structure Query Language است.
پایگاه های داده رابطه ای در اوایل دهه ۱۹۷۰ محبوبیت زیادی پیدا کرد، در آن زمان، ذخیره سازی بسیار گران بود بنابراین مهندسان نرم افزار به منظور کاهش تکثیر داده ها، پایگاه داده های خود را نرمال سازی می کردند ( در مقاله ای جدا این بحث را به صورت کامل مورد بررسی قرار خواهیم داد) . قبل از شروع توسعه پروژه ها با جزئیات برنامه ریزی شده مهندسان نرم افزار، با زحمت نمودار های پیچیده ای برای رابطه موجودیت (E-R یا ERD ) ایجاد می کردند تا اطمینان حاصل کنند که با دقت تمام داده هایی را که برای ذخیره آنها لازم است را پیش بینی کرده اند(برای ایجاد Schema جداول)، و کلی دردسر( اکنون با این تعاریف شاید از بانک های اطلاعاتی رابطه ای نگاه مناسبی در ذهن شما ایجاد نشده باشد اما باید گفت که هر کدام از این بانک های اطلاعاتی در مکان و جایگاه خودش مورد استفاده قرار می گیرد و هر کدام کاربرد خود را دارد).
انواع بانک های اطلاعاتی NoSQL:
۱.بانک های اطلاعاتی سندی ( Document Database)
داده ها در سند هایی ذخیره سازی می شوند که فرمت JSON می باشد، در این نوع بانک های اطلاعاتی یک جفت کلید-مقدار(Key-Value) وجود دارد که مقدار به عنوان یک داده قابل بازیابی و کلید همان نشانگر منحصر به فرد سند ذخیره می شود. اسناد واحد های مستقلی هستند که توزیع آنها را در چندین سرور همزمان با حفظ مکان داده آسان می کند و ما بدون هیچ مشکلی می توانیم روند کار را مشاهد کنیم .همچنین ناگفته نماند که بانک های اطلاعاتی برای ذخیره سازی و استفاده از داده های پراکنده و بی ساختار استفاده می شوند مانند : MongoDB, Elasticsearch
طراحی بانک های اطلاعاتی سندی
در این جا داده ها به صورت یک Collection از سند ها ذخیره می شوند(در بانک های اطلاعاتی رابطه ای نسبت به بانک های اطلاعاتی سندی جدول Collection و ردیف یا رکورد Document می باشد) برای مثال در یک وبلاگ اطلاعات مربوط به هر پست یا مقاله در یک Collection به شکل تو در تو ذخیره می شود، روش کاری جهت طراحی و ذخیره این نوع بانک ها به دو دسته تقسیم می شوند:
۱.۱. Embedding
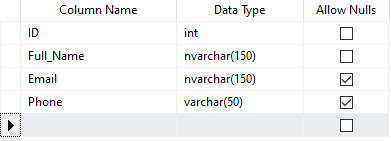
در این روش اطلاعات زیر مجموعه ی سند اصلی (Sub-document) در همان مجموعه اصلی ذخیره می شود، در نتیجه موجب بالا رفتن حجم سند اصلی می گردد. در تصویر زیر یک نمونه از ساختار این نوع طراحی را می توانید مشاهده کنید:
۲.۱. Referencing
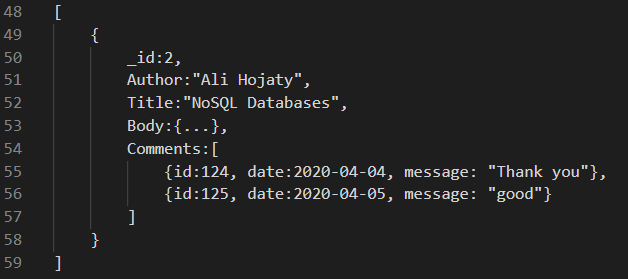
در این روش اطلاعات Sub-document در مجموعه ی دیگر و کلید آنها در مجموعه اصلی ذخیره می شود در نتیجه حجم اطلاعات مجموعه اصلی کاش یافته و کار با آن آسان می شود و پرس و جو ها سریعتر پاسخ داده می شوند.در تصویر زیر هم می توانید ساختار را مشاهد کنید :
توصیه ای در مورد پایگاه های داده سندی
در طراحی پایگاه های داده برای ذخیره سازی اطلاعات، در ارتباط های On-to-One بهتر است از روش Embedding استفاده شود و در ارتباط های One-to-Many و Many-to-Many در صورتی که اطلاعات کمتر از ۱۶ مگابایت باشد از Embedding و در غیر این صورت از Referencing استفاده کرد.
۲. پایگاه های داده کلید-مقدار) Key-Value Database )
در این نوع بانک های اطلاعاتی، کلید ها به صورت جدول Hash ذخیره می شوند تا بتوان آنها را سریعتر و ساده تر جستجو کنیم. این نوع پایگاه های داده دارای سرعت فراخوانی بسیار بالایی هستند کار با آنها بسیار ساده است. این پایگاه های داده کاربرد بسیار فراوانی را دارد برای مثال یکی از کاربرد های آن ذخیره سازی Session (جلسه) های کاربر (مانند ذخیره سازی اطلاعات کاربری در یک وب سایت)، ذخیره سازی داده ها به صورت Cheche، ذخیره سازی سبد خرید در یک فروشگاه اینترنتی، لیست آخرین بازدید کننده ها، صف بندی و... است که می توان به آن اشاره کرد.
اما یکی از مشکلات این نوع بانک های اطلاعاتی عدم وجود ویژگی Consistency (سازگاری) در آن ها است. اگر بخواهیم داده هایی را ذخیره سازی کنیم که دارای ارتباطات مختلفی باشند، این نوع پایگاه داده کارایی خود را از دست می دهد. این نوع بانک های اطلاعاتی معمولا در زمانی که حجم اطلاعات کم و فراخوانی آنها زیاد باشد بهترین گزینه است و می توان پایگاه داده های Redis, DynamoDB را معرفی کرد.
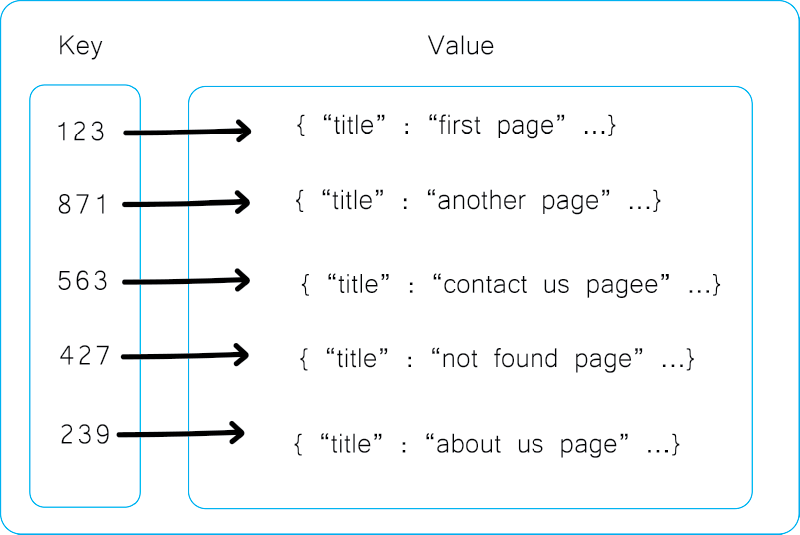
تصویر بالا نمونه ای از یک پایگاه داده ی کلید-مقدار است، ما توسط Key می توانیم خیلی سریع به Value دسترسی پیدا کنیم.
توصیه ای در رابطه با بانک های اطلاعاتی کلید-مقدار
گرچه این نوع پایگاه های داده میتواند به عنوان پایگاه داده اصلی پروژه باشد ولی بهتر است که در لایه Cache پروژه هایتان از آن بهره مند شوید.
۳. بانک های اطلاعاتی ستون گسترده (database Wide-Column Stores)
پایگاه های داده Wide-Column از لحاظ ظاهر مانند پایگاه های داده رابطه ای هستند اما با این تفاوت که Schema مشخصی ندارند و هر ستون در رکورد های مختلف می تواند شامل داده هایی با ساختار و نوع متفاوت باشد. پایگاه های داده ستون گسترده برای زمانی که شما نیاز به ذخیره مقادیر زیادی دارید عالی است و می توانید الگو پرس و جو خود را پیش بینی کنید برای مثال Cassandra, HBase نمونه هایی از این نوع بانک های اطلاعاتی می باشند، در تصویر زیر نمونه ای از این نوع پایگاه داده را می توانید مشاهد کنید:

از جمله کاربرد های این نوع پایگاه داده، می توان به ذخیره سازی Log سنسور ها در اینترنت اشیا، اطلاعات جغرافیایی، سیستم گزارش گیری، اطلاعات سری زمانی، ثبت وقایع Online، نرم افزار هایی با نرخ نوشتن بالا و... اشاره کرد.
شرکت های بزرگی که از این نوع پایگاه داده استفاده می کنند عبارتند از:
- نمایش اطلاعات اضافی در مورد خواننده و آهنگ ها در Spotify
- پیدا کردن دوستان در اطراف شخص در Facebook
- ارائه بیش از ۱۹۰ میلیارد توصیه محتوای شخصی در هر ماه در Outbrain
۴. پایگاه های داده گراف (Graph Databases )
از این نوع پایگاه های داده برای ذخیره سازی موجودیت ها و روابط بین آن ها استفاده می شود، معمولا در پایگاه داده هایی که اطلاعات به صورت سطر و ستون ذخیره می شوند، سرعت دسترسی به اطلاعات خوب است( به خصوص زمانی که از قابلیت ایندکس گذاری استفاده می کنیم)، این در حالی است که در بسیاری از مواقع به دلیل نیاز به سرعت بالای دسترسی به اطلاعات، سرعت خواندن و نوشتن داده ها، در پایگاه داده رابطه ای مناسب به نظر نمی رسد. این اتفاق زمانی رخ می دهد که می خواهید یک یا چند ادغام (join) بروی جداول مختلف یک پایگاه داده انجام دهید.
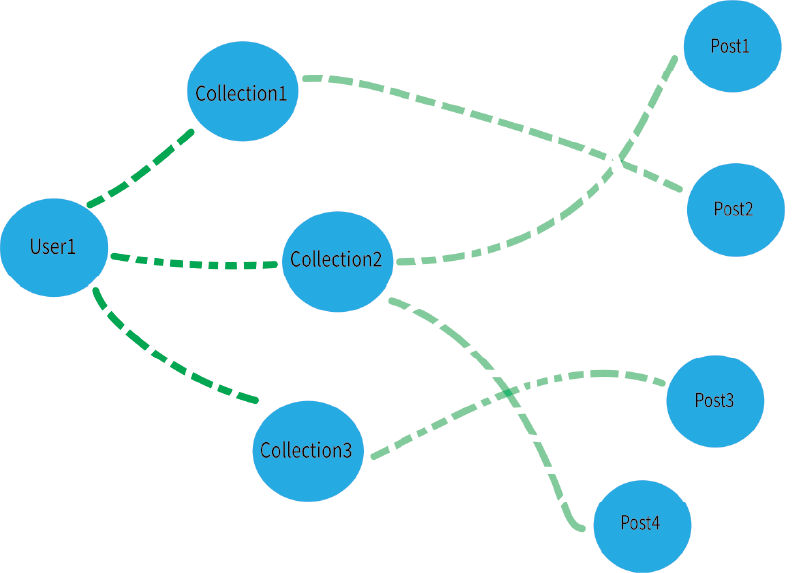
در این پایگاه داده هر موجودیت را یک گره و ارتباط آن را با گره دیگر یال در نظر می گیرد. زمانی که نیاز به جستجو سریع در میان داده های مرتبط با هم را دارید این نوع پایگاه داده انتخاب مناسبی می تواند باشد که Neo4j,JanusGraph نمونه های از این پایگاه داده می باشند.
این هم نمونه از پایگاه های داده گراف:
نتیجه گیری
در این مقاله پایگاه داده های NoSQL را مورد بررسی قرار دادیم. این نوع پایگاه های داده بسیار ساده بوده و مناسب برای ذخیره سازی اطلاعات غیر ساختار یافته توزیع شده است شما اکنون می توانید بنا بر هدفی که در ذهن دارید یکی از آن ها را انتخاب کرده و شروع به یادگیری آن کنید. همچنین با انواع این نوع بانک ها آشنا شده و درک بهتر نسبت به عملکرد آن دارید.








برای افزودن دیدگاه خود، نیاز است ابتدا وارد حساب کاربریتان شوید